Multimodal Neurons in Artificial Neural Networks
Explore the concept of multimodal neurons in artificial neural networks and how they enable AI models to process and integrate information from multiple data types, such as text, images, and audio, mimicking human-like perception and understanding across diverse modalities.

Artificial Intelligence (AI) has made remarkable progress through advancements in deep learning and neural networks. However, the human brain’s ability to process multiple types of information simultaneously such as sight, sound, and language has inspired a new frontier in AI: multimodal neurons.
These neurons enable machines to understand and integrate information from various data sources (modalities), making them more context-aware, intuitive, and intelligent. This article explores what multimodal neurons are, how they work in artificial neural networks, and the current research driving this innovative field forward.
Multimodality in Neural Networks
Multimodality refers to the capability of a system to process and combine data from different types of inputs, such as text, images, video, and audio.
In the human brain, multimodal perception helps us interpret complex real-world scenarios. Similarly, in AI systems, multimodal networks enable more robust decision-making by correlating diverse forms of information.
For example:
- A vision-language model like OpenAI’s CLIP can understand both textual and visual cues to associate an image with its description.
- Speech recognition models combine audio and textual data to accurately transcribe spoken language.
Multimodal integration allows neural networks to achieve better generalization, deeper understanding, and more human-like reasoning.
According to Precedence Research, the global Natural Language Processing (NLP) market was valued at USD 30.68 billion in 2024 and is projected to grow from USD 42.47 billion in 2025 to nearly USD 791.16 billion by 2034, exhibiting a compound annual growth rate (CAGR) of 38.40% during 2025–2034. This rapid expansion underscores the increasing adoption of multimodal AI technologies across industries.
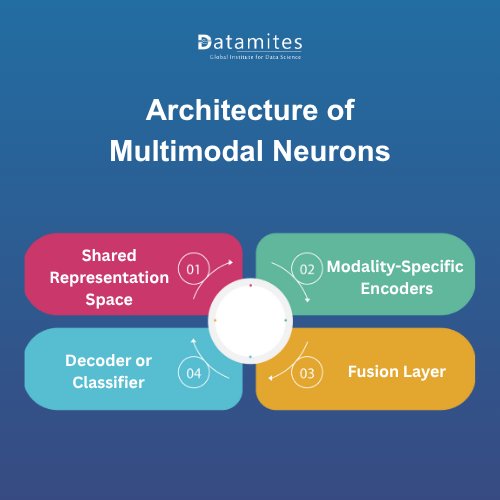
Architecture of Multimodal Neurons
The architecture of multimodal neurons is designed to merge multiple data representations into a shared embedding space. These neurons act as connective hubs that process and align different modalities for unified understanding.
Key Components Include:
Modality-Specific Encoders: Separate encoders process different data types for example, CNNs for images and Transformers for text.
Fusion Layer: The fusion layer combines encoded representations to form a cohesive understanding. Common techniques include:
- Concatenation
- Attention mechanisms
- Cross-modal transformers
Shared Representation Space: After fusion, all modalities are represented in a common latent space, allowing multimodal neurons to correlate patterns across inputs.
Decoder or Classifier: The final stage translates the multimodal understanding into actionable outputs such as predictions, classifications, or generative content.
This architecture enables the network to handle cross-modal learning a key feature that bridges gaps between vision, language, and sound.
Functioning and Activation Patterns
Multimodal neurons activate when they detect features or concepts across multiple modalities. A neuron might respond to both the word “dog” and an image of a dog similar to how neurons in the human brain’s temporal lobe fire in response to specific people, objects, or ideas.
How They Work:
- When input data from different modalities is fed into the system, multimodal neurons identify shared semantic features.
- These neurons develop cross-modal associations, enabling models to understand relationships beyond a single type of input.
- Activation patterns often reveal concept-level understanding, not just raw data processing.
This behavior gives AI systems contextual depth; they can link text and visuals meaningfully, leading to improved performance in image captioning, video understanding, and natural language grounding.
Refer these below articles:
- Generative Adversarial Networks (GANs)
- What Is Vertex Artificial Intelligence?
- What is Simple Linear Regression
Multimodal Neurons in Artificial Neural Networks
In artificial neural networks (ANNs), multimodal neurons serve as concept detectors that unify diverse sensory data. They have been instrumental in the evolution of large-scale AI models.
Notable Applications:
- CLIP (Contrastive Language–Image Pretraining): Developed by OpenAI, CLIP uses multimodal neurons to connect text and visual data, enabling zero-shot image classification.
- DALL·E and GPT-4: These models employ multimodal neurons for image-text synthesis, allowing AI to both understand and generate visual content.
- Self-driving Vehicles: Multimodal networks process visual, radar, and LiDAR data to enhance situational awareness and decision-making.
- Healthcare and Diagnostics: AI systems integrate image scans, patient histories, and lab data to provide more accurate medical predictions.
The emergence of multimodal neurons marks a step toward Artificial General Intelligence (AGI) where AI systems understand information in a holistic, human-like way.
Research and Recent Developments
Recent studies have focused on improving multimodal neuron efficiency and interpretability. Some notable developments include:
- Large-Scale Pretrained Models: Models like OpenAI’s CLIP and Google’s ALIGN utilize multimodal neurons to learn from massive datasets.
- Neuroscience-Inspired Approaches: Researchers are modeling artificial multimodal neurons based on insights from human brain studies.
- Cross-Modal Contrastive Learning: Techniques that optimize how neurons align representations from different modalities for better performance.
These advances continue to push the boundaries of what AI can achieve, making multimodal neurons a pivotal area of ongoing research.
Multimodal neurons in artificial neural networks represent a powerful mechanism for integrating and understanding complex data from multiple sources. From enhancing model performance to enabling human-like reasoning, their role is central to the evolution of modern AI. As research progresses, these neurons are likely to unlock even more sophisticated AI applications, shaping the future of intelligent systems.
Now is the ideal time to begin your artificial intelligence journey. Enrolling in artificial intelligence training in bangalore, Pune, Hyderabad, Ahmedabad, Coimbatore, Chennai, or Mumbai equips you with practical skills, live project experience, and expert career guidance. With increasing demand for skilled professionals, the right ai and ml training can open doors to diverse and rewarding career opportunities in ai and ml across industries.
Bangalore, often referred to as the “Silicon Valley of India,” has emerged as a leading global hub for Artificial Intelligence and Machine Learning . With its vibrant ecosystem of world-class educational institutions, a thriving startup scene, and substantial investments from global technology leaders, the city has become a prime destination for pursuing an AI and Machine Learning course in Bangalore. This strong synergy between academia, industry, and innovation continues to drive Bangalore’s reputation as a powerhouse for AI-driven talent and research.
DataMites is a leading training institute for Artificial Intelligence courses in Bangalore, along with programs in Machine Learning, Data Science, and other in-demand technologies. Learners gain access to globally recognized certifications accredited by IABAC and NASSCOM FutureSkills, supported by comprehensive career services that include resume building, mock interviews, and strong industry connections. Datamites Bangalore training centers located in Kudlu Gate, BTM Layout, and Marathahalli, DataMites provides both online and classroom learning options to suit diverse learning needs.
Read these below articles: