Introduction to ATTENTION in NLP for Beginners

Sequence to sequence modelling: (RNN)
We might get a lot of sequence to sequence tasks and that needs to be automated. Let’s look at how we can address them using sequence to sequence modelling.
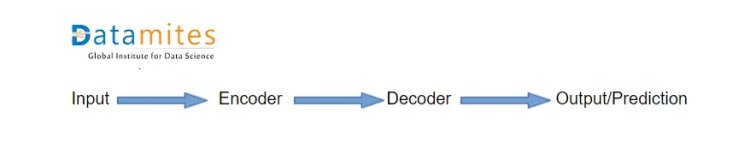
Let’s take a pair of encoder and decoder where:
- Encoder summarizes all the information.
- The decoder uses that summarized information of the encoder for prediction or output.
We can achieve this by using RNN (Recurrent Neural Network). We can do the following things for this:
- Embedding of words to a vector.
- Make the final state of the encoder convey the information to the decoder.
Let’s take an example as below:
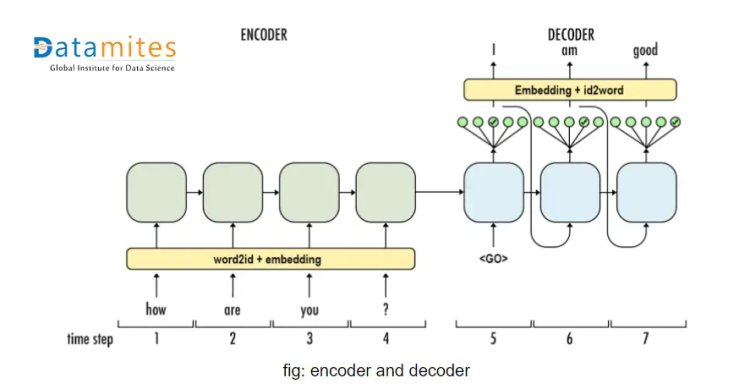
IN ENCODER: Here we can see, we have different blocks that take the output from the previous block and the next word from the input sentence. Afterwards, they compute the next hidden state. We provide new words from the input sentence each time and it learns more and more about the whole input sequence.
IN DECODER: Its working is almost similar to an encoder with a little bit different. Input for each decoder block is input from the output of the previous block and hidden state from the previous block.
DRAWBACKS:
- We keep on adding words linearly (i.e one word after another) in order, and it may cause the loss of information starting from the beginning portion of the input sentence for each word we add.
- For very long sequences, the information won’t be complete that will be conveyed to the decoder.
Attention:
To address this loss of information in sequence to sequence modelling, attention was introduced.
What I have done here is, I am generalizing the concept ‘attention’ based on different articles and videos I have seen so that every beginner gets out of the dilemma of attention.
Let’s take a simple example below:
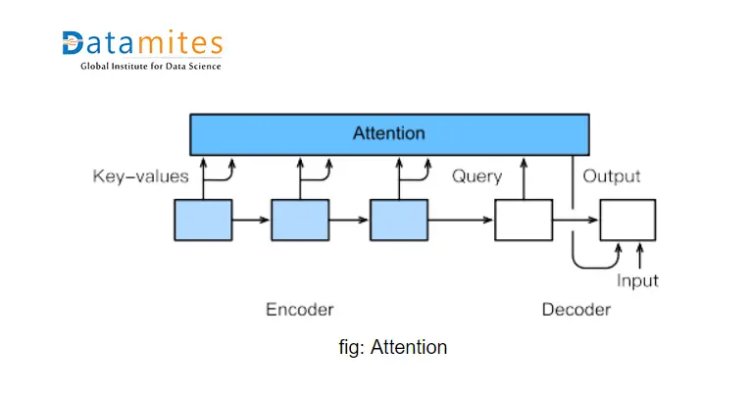
Lets elaborate it with look-alike as the same previous example,
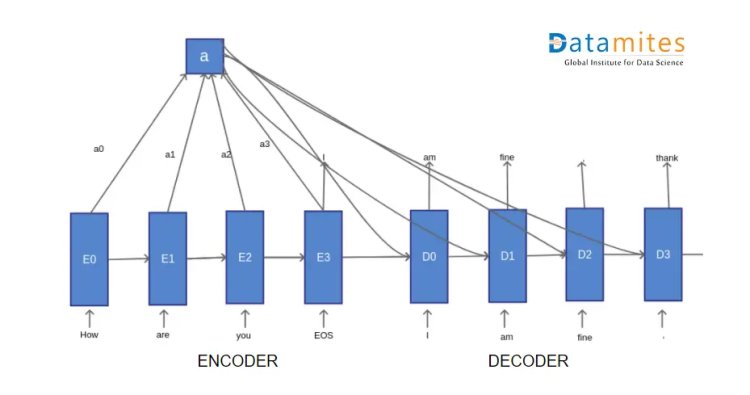
Suppose we are at D1 phase, we have hidden state D0. Previously with sequence to sequence model, we would have used predicted word from D0 (ie “am”) with hidden state D0 and predicted the output as “fine”.
But as in the figure, we see new input from attention/context vector(a) which is a weighted sum of all hidden states from encoder i.e (a0, a1, a2, a3). It defines how the current decoding phase is related to each encoding phase or how the current state of the decoder is related to the global input sentence and hence it improves the decoding phase.
So this is how encoder is related to our current state in the decoding phase. This is how the attention mechanism works in general i.e in the decoding phase we add a new context vector (attention) that conveys more global information to the decoding state.
Advantage: By using attention, this model tries to gather more information that was lost in sequence to sequence modelling.
I am not going to use any mathematical expression over this article. For mathematical background and implementation visit
Attention in NLP (https://arxiv.org/pdf/1902.02181.pdf),
Andrew Ng youtube video (https://www.youtube.com/watch?v=SysgYptB198&ab_channel=Deeplearning.ai)