Introduction to Implementing Neural Network

What do you know about Artificial Neural Network?
A Neural Network is a chain of algorithms that attempts to recognize underlying relationships in an array of data by mimicking the way the human brain operates. Neural Networks can either be biological or artificial, that is they can be formed by biological neurons or artificial neurons. Artificial Neurons can be used to solve AI challenges.
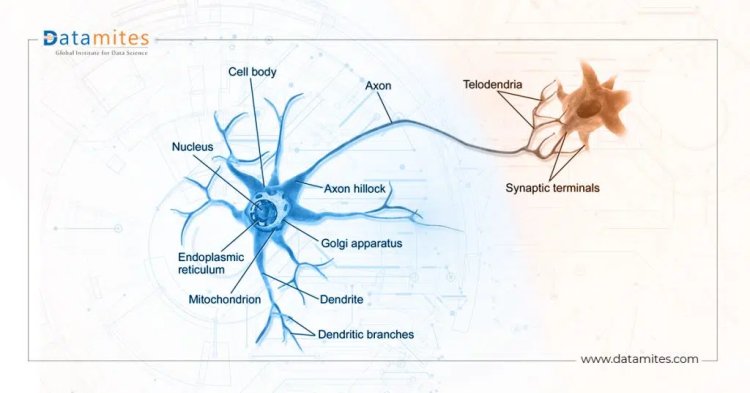
Biological neural networks have influenced the development of artificial neural networks, but they are rarely exact replicas of their biological counterparts. Let us understand the different components of artificial neural networks.
Neuron (Perceptron model)
To start with, one must understand the perceptron model. A perceptron is a single neuron that takes input and produces output. Here is a simple linear perceptron model.
The Linear Unit
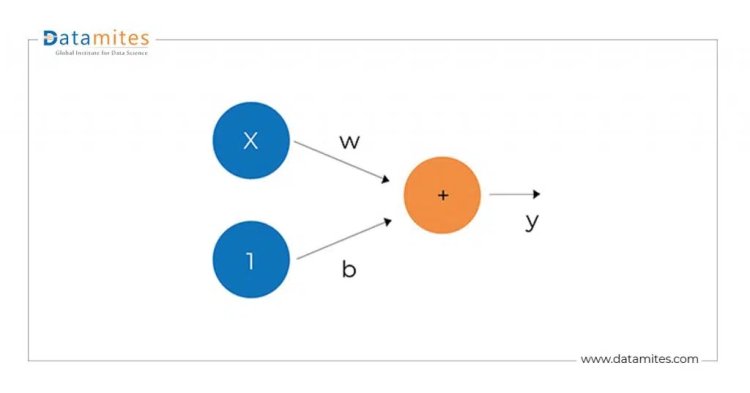
The perceptron model does the following steps.
The input is x. Its connection to the neuron has a weight which is w. Whenever a value flows through a connection, you multiply the value by the connection’s weight. For the input x, what reaches the neuron is w * x. A neural network “learns” by modifying its weights.
The b is a special kind of weight we call the bias. The bias doesn’t have any input data associated with it; instead, we put a 1 in the diagram so that the value that reaches the neuron is just b (since 1 * b = b). The bias enables the neuron to modify the output independently of its inputs.
But, data is not always linear!
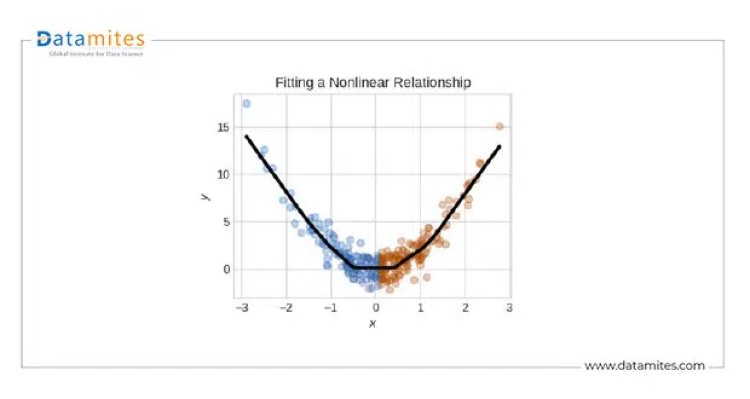
We can show non-linear relationships in data using Activation functions. In simple words, in order to fit curves, we will need to use activation functions(mathematical functions). There are many activation functions available such as Relu, Selu, elu, tanh, etc. here is the list of activation functions to experiment with https://en.wikipedia.org/wiki/Activation_function
The below figure shows the modified version of the perceptron model. The model below includes activation functions that are used to show the non-linearity in data.
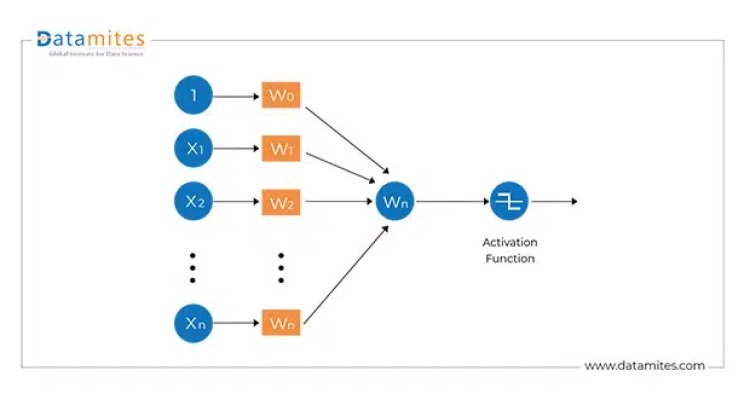
The steps that are carried out in the modified model are as follows
- Inputs (x1, x2..etc) along with random weights are fed to the neurons
- Each neuron performs a weighted summation of input, weights, and bias (constants)
- The final output goes to the activation function, the activation function outputs the final output.
In order to build a neural network, the layers of neurons have to be stacked one after the other. Which will eventually result in a multi-layer perceptron model (neural network).
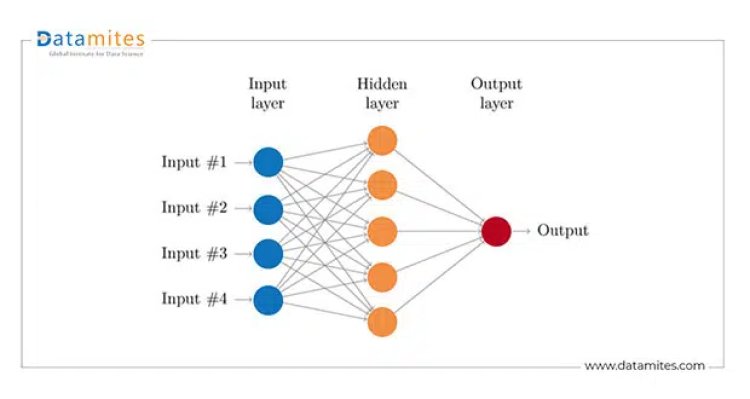
The neural network consists of an input layer, hidden layers(one or more), and an output layer.
Every neuron in one layer is connected to every other layer of neurons, forming a dense neural network. The connections from layer to another layer is called synapse in the context of biological neural network. As mentioned above, every input layer, hidden layer, and output layer will have activation functions.
The commonly used activation functions in the input layer and hidden layer are Relu and tanh . However, in the output layer, the sigmoid activation function is used for binary classification and softmax for multiclass classification problems. But, for the regression analysis, the activation function changes for the output layer such as the Linear activation function.
A neural network requires resources, training data, ability, and time to construct. To create a neural network, most data mining platforms provide at least the neural network algorithm. In this article, we’re going to work through a classification problem with the Keras framework. In other words, taking a set of inputs and predicting what class those sets of inputs belong to.
The steps required to build a neural network are as follows:
ANN Implementation in Python
- 1. Data Preprocessing
- 1.1 Import the Libraries
- 1.2 Load the Dataset
- 1.3 Split Dataset into X and Y
- 1.4 Split the X and Y Dataset into the Training set and Test set
- 1.6 Perform Feature Scaling
- 2. Build Artificial Neural Network
- 2.1 Import the Keras libraries and packages
- 2.2 Initialize the Artificial Neural Network
- 3. Train the ANN
- 3.1 Fit the ANN to the Training set
- 4 Predict the Test Set Results
- 5. Make the Confusion Matrix
Conclusion
For implementation, we use the Pima Indians Diabetes Dataset. You can download the dataset from https://www.kaggle.com/uciml/pima-indians-diabetes-database. Artificial Neural networks can be used for both classification and regression. And here we are going to use ANN for classification.
The dataset has the following features
The datasets consist of several medical predictor variables and one target variable, Outcome. Predictor variables include the number of pregnancies the patient has had, their BMI, insulin level, age, and so on.
1.1 Import the Libraries
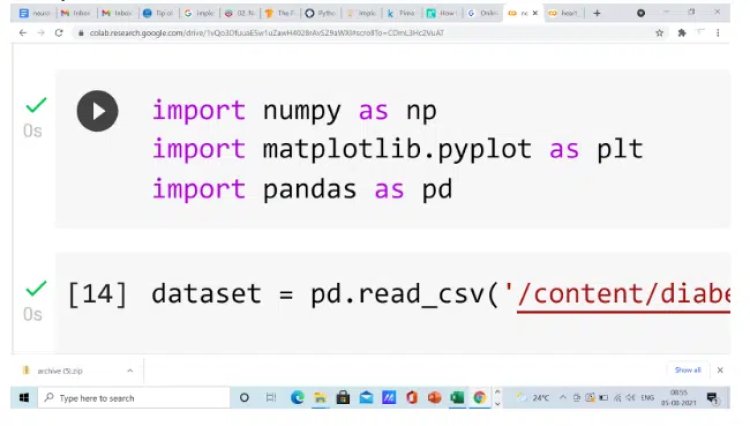
NumPy is a Python package that may be used to execute a variety of mathematical and scientific activities. NumPy is a Python library for working with arrays. It also provides functions for working with matrices, Fourier transforms, and linear algebra. Matplotlib is a plotting library that is used for creating a figure, plotting an area in a figure, plotting some lines in a plotting area, decorating the plot with labels, etc. Pandas is a tool used for data wrangling and analysis.
So in step 1, we imported all required libraries. Now the next step is-
1.2 Load the Dataset
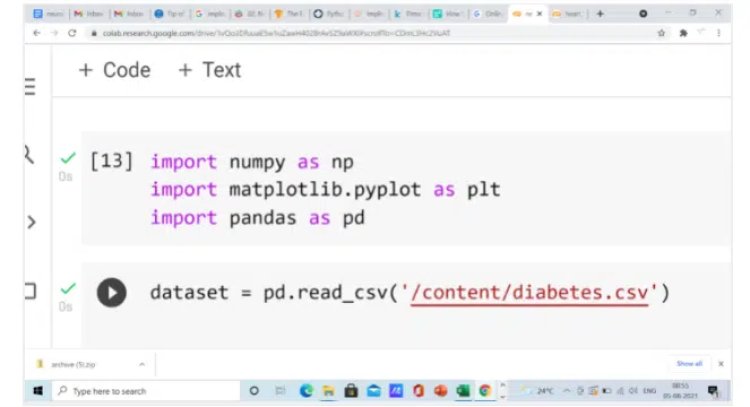
So, when you load the dataset after running this line of code, the output is shown like this
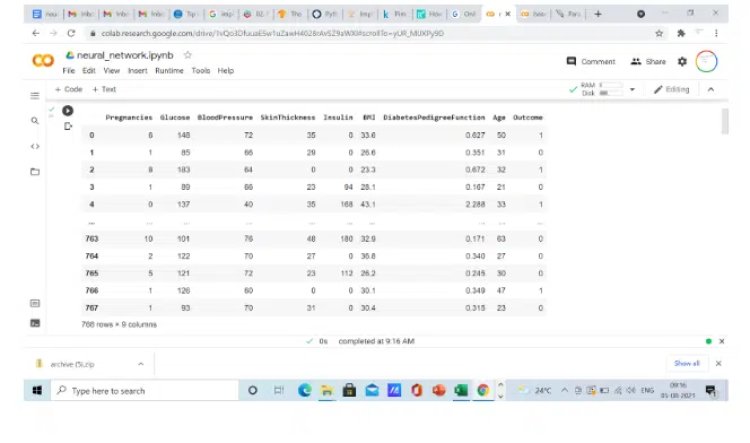
As you can see in the dataset, there are 8 independent variables and 1 dependent variable.
1.3 Split Dataset into X and Y
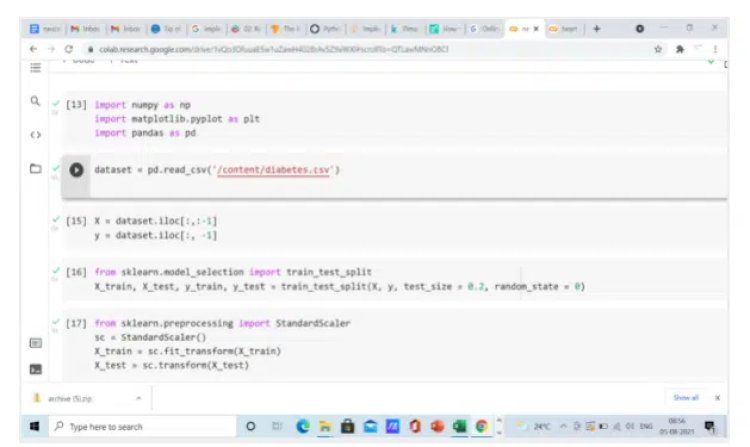
We will also split the independent variables in X and a dependent variable in Y.
1.4 Split the X and Y Dataset into the Training set and Test set
We will use sklearn train_test_split class, to split the data into 80% percent train data and 20% test data
1.6 Perform Feature Scaling
Since the neural network performs well when the data is scaled. We will use a standard scaler object to standardize the independent variables
2. Build Artificial Neural Network
2.1 Import the Keras libraries and packages
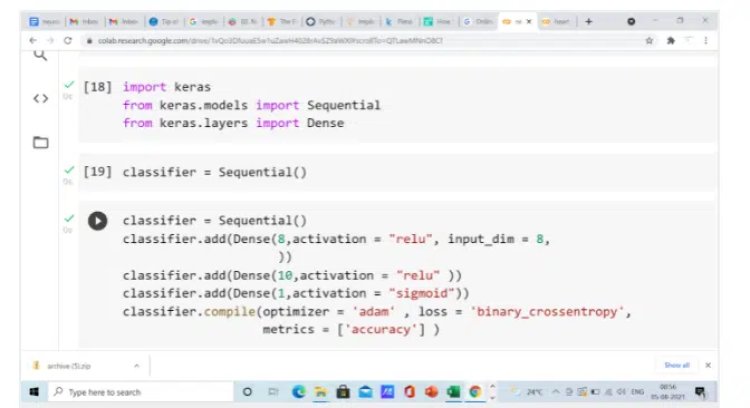
Now, it is time to build a sequential model using Keras’s sequential class. Keras sequential is so simple, that you keep adding layers of neurons to build the neural network.
2.2 Initialize the Artificial Neural Network
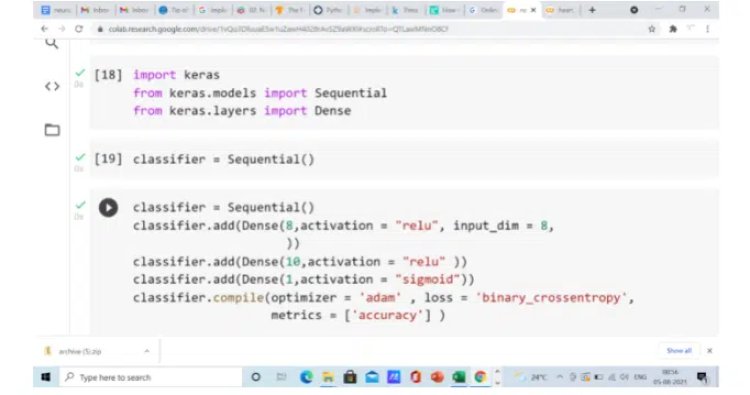
We initialize the sequential object and start adding the input layer, hidden layer, and output layer. We use the add function to add all these layers one after the other. The input layer has 8 neurons as the first parameter, relu as the activation function as the second parameter and 8 input dimensions as the third parameter, this is because we have 8 independent variables in our dataset. The hidden layer has 10 neurons and relu as an activation function. The last layer i.e output layer has one neuron because we need to predict whether a person is diabetic or non-diabetic. The activation function used in the last layer is the sigmoid activation function.
Finally, we need to compile the model, the compile function includes an adam(Adaptive Moment Estimation) optimizer function to tune the weights of the model, the loss function is binary cross-entropy (normally used for binary classification problem) and the metric we want to monitor is accuracy. The aim is to reduce the loss and improve the accuracy of the neural network.
Note: this article will not discuss the different optimizers used in neural networks. However, optimizers are mathematical functions that are used to tune the weights of the neural network in order to improve the model’s predictive capabilities
3. Train the ANN
3.1 Fit the ANN to the Training set
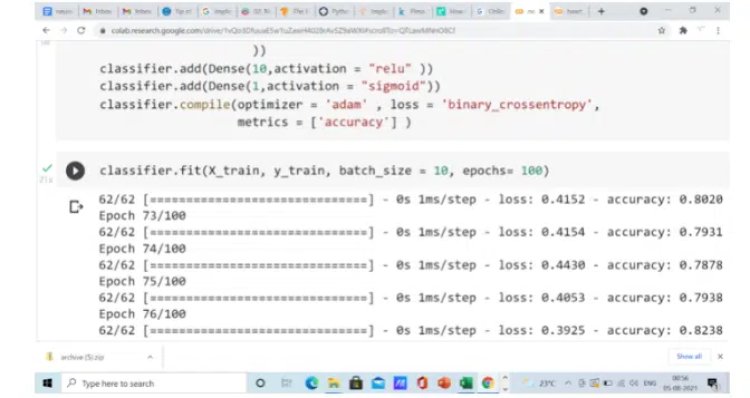
Once the model is compiled, we need to train the neural network. The fit function in Keras does that job. The first parameter in the fit function is the 80% training part, the second parameter is the batch size, which specifies the number of training samples to be passed to the model for the training purpose. The last parameter is an epoch, epoch is the number of times you iterate through the entire training set in order to train the model. As you can see, as the number of epochs increases the accuracy of the model. However, care should be taken not to overfit the model by keeping a large number of epochs.
- Predict the Test Set Results
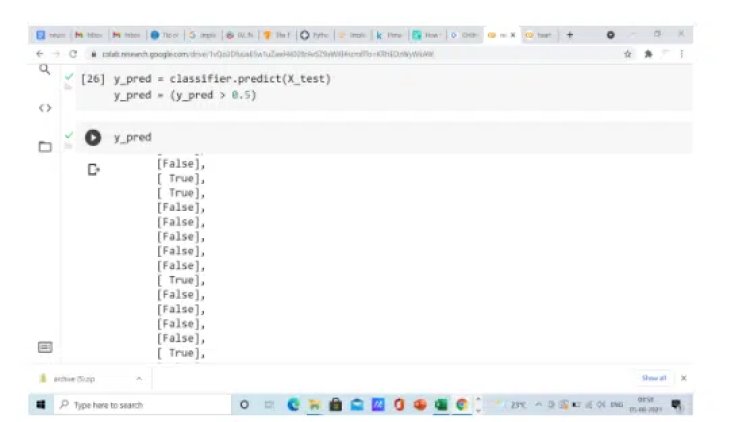
y_pred > 0.5 means if y-pred is in between 0 to 0.5, then this new y_pred will become 0(False). And if y_pred is larger than 0.5, then the new y_pred will become 1(True).
After running this code, you will get y_pred something like the above.
It is easy to explain how predictions are predicted correctly and how many are predicted incorrectly when we have a small dataset. But when we have a large dataset, it’s quite impossible. And that’s why we use a confusion matrix, to clear our confusion.
- Make the Confusion Matrix
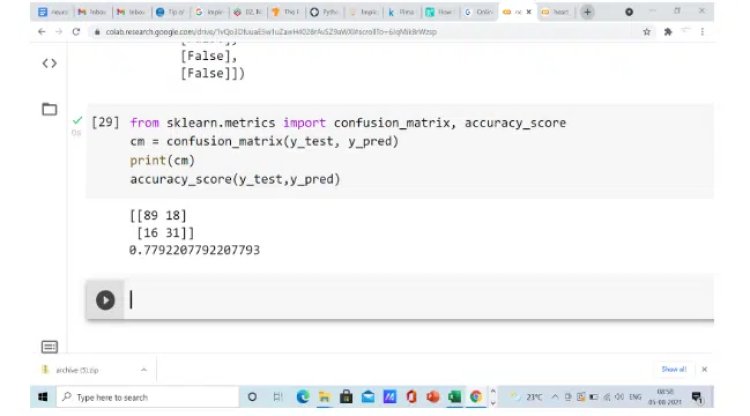
In the above snapshot, the accuracy we obtained is 77%. That’s a pretty good one. However, you can always tune your model to improve the accuracy. Here is some common tuning we normally do to improve the model performance
Improving a model
Steps to improve your neural network model
- Creating a model– where you might want to add more layers, increase the number of hidden units (also called neurons) within each layer, and change the activation functions of each layer.
- Compiling a model– you might want to choose a different optimization function (such as the Adam optimizer, which is usually pretty good for many problems) or perhaps change the learning rate of the optimization function.
- Fitting a model– perhaps you could fit a model for more epochs (leave it training for longer).
There are many different ways to potentially improve a neural network. Some of the most common include: increasing the number of layers (making the network deeper), increasing the number of hidden units (making the network wider), and changing the learning rate. Because these values are all human-changeable, they’re referred to as hyperparameters) and the practice of trying to find the best hyperparameters is referred to as hyperparameter tuning.
Conclusion
In this article, we tried explaining neural networks and their implementation using the Keras framework. Hope you have understood.
Happy Learning!
Complete code:
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
dataset = pd.read_csv(‘/content/diabetes.csv’)
X = dataset.iloc[:,:-1]
y = dataset.iloc[:,-1]
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.2,random_state = 0)
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
import keras
from keras.models import Sequential
from keras.layers import Dense
classifier = Sequential()
classifier.add(Dense(8,activation = “relu”, input_dim = 8,
))
classifier.add(Dense(10,activation = “relu” ))
classifier.add(Dense(1,activation = “sigmoid”))
classifier.compile(optimizer = ‘adam’ , loss = ‘binary_crossentropy’,
metrics = [‘accuracy’] )
classifier.fit(X_train,y_train,batch_size = 10,epochs= 100)
y_pred = classifier.predict(X_test)
y_pred = (y_pred > 0.5)
from sklearn.metrics import confusion_matrix, accuracy_score
cm = confusion_matrix(y_test, y_pred)
print(cm)
accuracy_score(y_test,y_pred)
DataMites is a global training institute for artificial intelligence and machine learning courses. The certification courses are aligned with IABAC syllabus.