How to Build Your First Machine Learning Model?
Building your first machine learning model involves a step-by-step process that starts with understanding the problem you want to solve. With consistent practice and learning, you'll gain the skills to create more complex models over time.

Are you fascinated by the idea of machines making decisions on their own? Ever wondered how Netflix recommends shows you'll love or how email filters catch spam so accurately? Welcome to the world of machine learning where data meets intelligence. If you're a beginner eager to take your first steps into this exciting field, you're in the right place. In this blog, we’ll guide you through a simple, step-by-step process to build your very first machine learning model from defining the problem to deploying your solution. No prior experience? No problem. Let’s demystify machine learning and turn your curiosity into capability.
What is Machine Learning?
Machine learning is a subset of artificial intelligence (AI) that allows computers to learn from data without being explicitly programmed. Instead of following hard-coded rules, ML systems identify patterns in data and make decisions or predictions based on that learning.
At its essence, machine learning is about training algorithms using vast amounts of data, allowing them to learn patterns and improve performance over time. The more data a model processes, the smarter and more precise it becomes. According to a report by Grand View Research, the global artificial intelligence (AI) market is projected to reach an astounding USD 1.81 trillion by 2030, highlighting the rapid growth and immense potential of this transformative technology.
There are three main types of machine learning:
- Supervised Learning: Learning from labeled data (e.g., spam detection in emails).
- Unsupervised Learning: Learning from unlabeled data to find hidden patterns (e.g., customer segmentation).
- Reinforcement Learning: Learning by interacting with the environment through trial and error (e.g., training robots or game-playing AI).
What is a Machine Learning Model?
A machine learning model is a mathematical representation that learns from data to make predictions or decisions. It is the result of the training process in machine learning. The model takes input data, processes it, and produces an output such as classifying an email as spam or not spam.
For example, an image recognition model trained on thousands of labeled images of cats and dogs can accurately determine whether a new image is of a cat or a dog.
Machine learning models vary in complexity, ranging from simple linear regression models to deep neural networks with millions of parameters. By 2030, artificial intelligence is projected to boost global GDP by 26%, contributing an estimated $15.7 trillion to the global economy.
Refer these below articles:
- Best Programming Languages for Artificial Intelligence Development
- AI in Everyday Life: How You’re Already Using Artificial Intelligence
- Understanding Machine Learning: Basics for Beginners
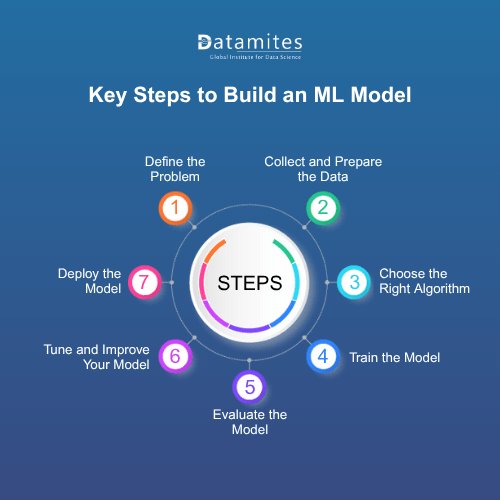
Key Steps in Building a Machine Learning Model
While different types of machine learning use varied training approaches, most models follow a common set of basic steps. Successful projects begin with clear planning and a thorough understanding of the organization's specific requirements.
Step 1: Define the Problem You Want to Solve
The first and most critical step in any machine learning project is to clearly define the problem. Without a well-defined problem, you risk wasting time, resources, and data.
Ask yourself:
- What decision or prediction do I want the model to make?
- What is the desired outcome?
- Is this a classification, regression, clustering, or recommendation problem?
Example:
- If you're a retailer and want to predict future sales, your problem is a regression problem because you're trying to predict a continuous value (sales amount).
- Defining the problem helps determine the right kind of data, algorithm, and evaluation metrics you'll use.
Step 2: Collect and Prepare the Data
Once the problem is clear, the next step is data collection and preparation often considered the most time-consuming part of the process.
Data Collection
- You can gather data from various sources:
- Internal databases (CRM, ERP)
- Public datasets
- APIs and web scraping
- IoT sensors and devices
Data Preparation
After collecting data, you must clean and preprocess it:
- Handle missing values: Fill or remove missing data.
- Remove duplicates and outliers: Ensure consistency and accuracy.
- Normalize or scale: Bring data to a common scale.
- Feature engineering: Create new meaningful variables that enhance model performance.
- Split the data: Divide the dataset into training, validation, and test sets.
High-quality data is essential for building accurate machine learning models. The saying goes: "Garbage in, garbage out."
Step 3: Choose the Right Algorithm
Choosing the right machine learning algorithm depends on the nature of your data and the problem you're solving.
Common ML Algorithms:
- Linear Regression: For predicting continuous values.
- Logistic Regression: For binary classification problems.
- Decision Trees and Random Forests: Great for interpretability and handling complex datasets.
- Support Vector Machines (SVMs): Ideal for classification problems with high-dimensional data.
- K-Nearest Neighbors (KNN): Simple and effective for small datasets.
- Naive Bayes: Good for text classification and spam detection.
- Neural Networks: Best for image recognition, natural language processing, and large-scale datasets.
Each algorithm has its strengths and limitations, so it's crucial to experiment and choose the one that fits your data best.
Step 4: Train the Model
Now comes the core of the machine learning process training the model. This involves feeding your training data into the algorithm and allowing it to learn patterns and relationships.
During training:
- The model adjusts internal parameters (like weights in neural networks).
- It minimizes errors using cost or loss functions.
- It uses optimization techniques like gradient descent to improve predictions.
It’s important to monitor for overfitting, which happens when the model performs well on training data but poorly on unseen data. Using a validation set helps detect and mitigate overfitting.
Step 5: Evaluate the Model
After training, it's crucial to evaluate the model's performance on a separate test dataset. This step ensures that the model generalizes well and can make accurate predictions on real-world data.
Evaluation Metrics:
- Accuracy: Percentage of correct predictions.
- Precision and Recall: Useful in imbalanced classification problems.
- F1 Score: Harmonic mean of precision and recall.
- ROC-AUC: Measures how well the model distinguishes between classes.
- Mean Squared Error (MSE) and R-squared: For regression models.
A model that performs well on both training and testing data is considered robust and generalizable.
Read these below articles:
Step 6: Tune and Improve Your Model
Model tuning, also known as hyperparameter optimization, helps enhance performance. Most algorithms have parameters you can adjust to improve results.
Techniques to Improve Model Performance:
- Grid Search or Random Search: For hyperparameter tuning.
- Cross-validation: Splits the data multiple times to ensure consistent performance.
- Ensemble Methods: Combine multiple models (e.g., bagging, boosting) to increase accuracy.
- Feature selection: Remove irrelevant features to reduce noise.
- Add more data: More diverse data can improve model learning.
Experimenting and iterating are key in machine learning. Don’t be afraid to go back and forth between steps.
Step 7: Deploy the Model
Once your model performs well, it's time to deploy it into production so it can start making real-world predictions.
Deployment Options:
- Web APIs: Expose the model as an endpoint using Flask, FastAPI, or Django.
- Cloud platforms: AWS SageMaker, Google Cloud AI Platform, Microsoft Azure ML.
- Embedded systems: Deploy on mobile apps or IoT devices.
After deployment, it’s important to monitor the model for performance drift, as real-world data can change over time.
Also consider setting up:
- Logging and alerts
- Retraining pipelines
- Version control for models
Machine learning is more than just algorithms; it's about leveraging data to solve real-world problems. Every stage in the machine learning pipeline plays a critical role in building a successful model from clearly defining the problem and preparing the data to choosing the right algorithm, training, evaluating, tuning, and ultimately deploying the model. According to ABI Research, the generative AI market is expected to grow at a compound annual growth rate (CAGR) of 29%, rising from USD 37.1 billion in 2024 to USD 220 billion by 2030 underscoring the accelerating adoption and impact of AI technologies.
DataMites is a globally recognized training institute specializing in Artificial Intelligence, Data Science, and Machine Learning. The DataMites Artificial Intelligence Institute in Chennai offers comprehensive AI programs that provide learners with a strong foundation in both theoretical concepts and practical applications.
Artificial Intelligence Course in Chennai offer a diverse range of courses designed for students, working professionals, and AI enthusiasts. These programs typically include live projects and internships, ensuring hands-on experience and real-world application of AI concepts.