Various types of Sampling Techniques with examples

To validate any outcome in research, data plays a very important role. One can do a statistical analysis of the data to verify the results. But, if the dataset is very large, it is difficult to analyze it. For example: If we want to find how many languages students can speak in a country. It is very difficult to collect reliable conclusions on such large data because a lot of data will be missing, resource and budget constraints, accessibility constraints etc. The solution to this problem is to take a subset of the data and analyze it.
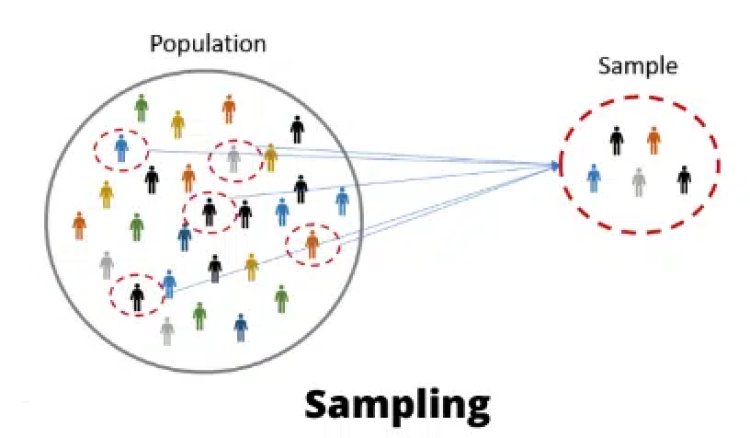
The entire set of data is referred to as the Population, whereas a subset of the population is referred to as the Sample. The sample is supposed to represent the entire population, and the findings made from the samples can be extrapolated to the entire data set. The population can be a collection of people, things, events, or organisations. Sampling is the process of collecting data from a small subset of the population and then using it to generalise over the complete group.
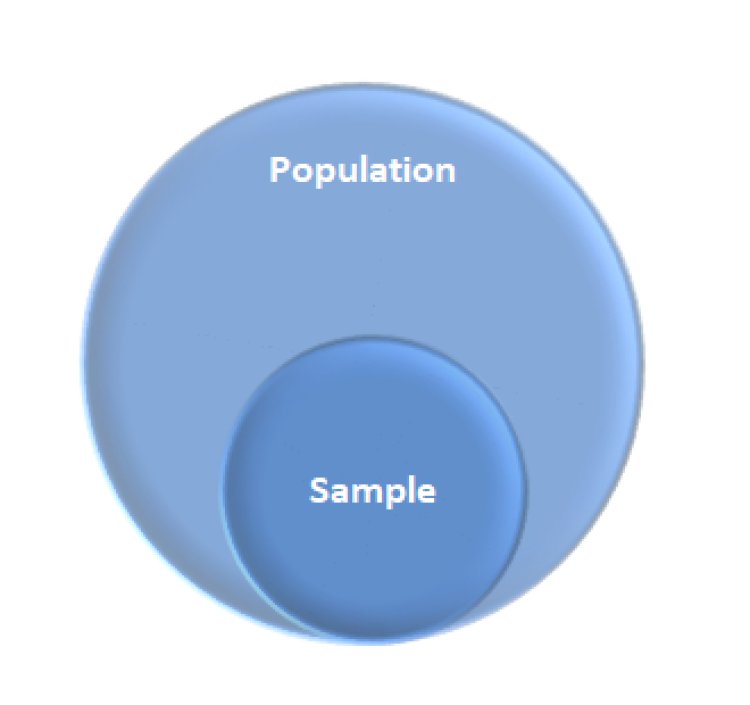
Sample as Subset of Population
The Cochran formula: It is very important to find out how many samples we need to collect for our research. The Cochran formula is used to decide the ideal sample size.
There are various techniques to select samples from the population. It is very important to select the correct sampling technique to collect samples from the population.
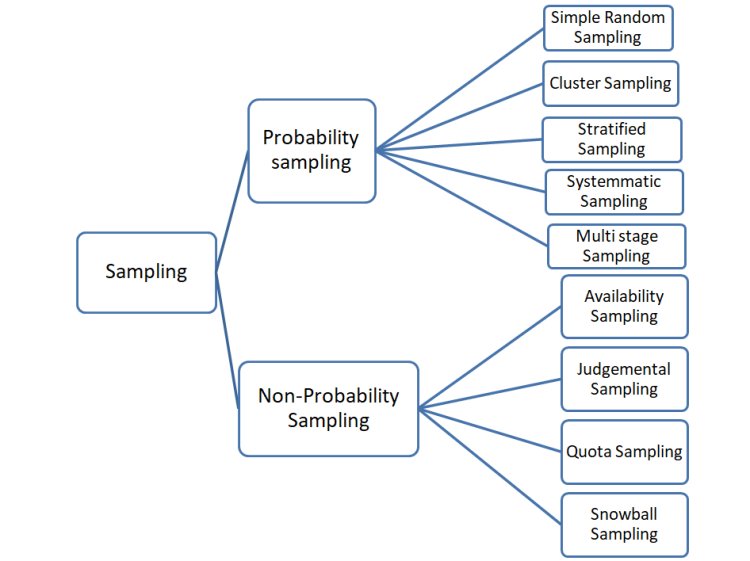
The sampling techniques can be broadly divided into 2 types:
1. Probability sampling
2. Non-Probability sampling.
Let’s understand these techniques in detail.
Types of Sampling
Probability sampling: In this type of sampling, all the elements of the population have the chance of being selected. That means all the units of the population have some fixed probability of being selected as samples. For example, in a group of 500 people, everyone has a 1/500 chance of being selected as a part of the sample.
Refer this article to know: Support Vector Machine Algorithm (SVM) – Understanding Kernel Trick
Techniques used in probability sampling are:
1. Simple Random Sampling: In this type of sampling, members are chosen randomly from the population, merely by chance. This can be done by either putting chits in a bowl like a lottery system or spinning the wheel. The advantage of simple random sampling it that it is easy cost-efficient, reliable and represents the whole population.

2. Cluster Sampling: In this type of sampling, the whole population is divided into some groups or clusters. Units with similar characteristics are kept in one cluster. For example, People can be grouped according to their age or country.
These clusters are also known as strata. Now, the researcher will pick some strata (according to the requirement and resources) randomly and perform his research on that.
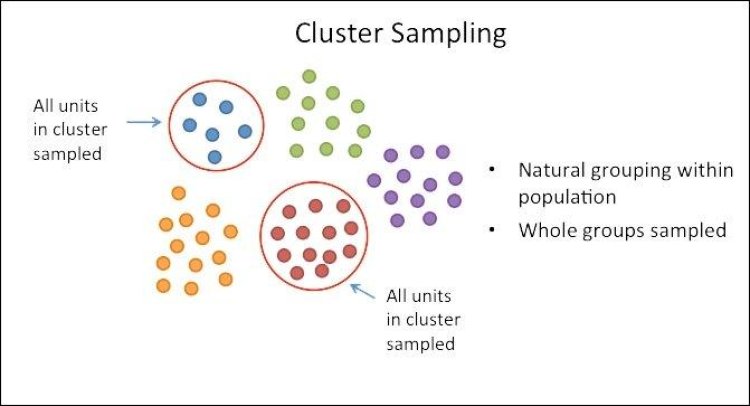
If the selected cluster is very large, then the researcher can again perform the sampling on the selected cluster. This is known as multi-stage cluster sampling.
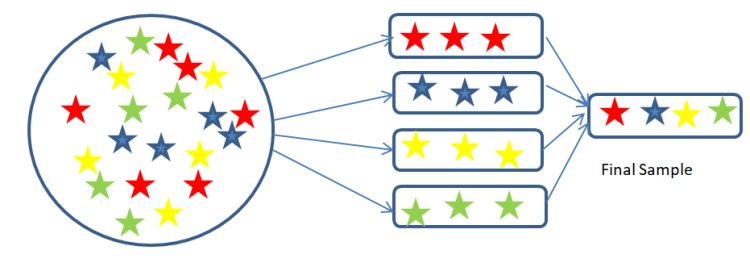
3. Stratified Sampling: In this type of sampling, the population is divided into strata according to some similar characteristics. Then members are chosen from each stratum to make the final sample. The advantage of this type of sampling is that we can have all types of samples from all the groups.
Example: If we want to find a review of a book in a country. We can divide the population according to the age groups like 18-25years, 25-35 years, 35-45years, 45-55 years and 55-65 years. Each age group represents each stratum. Then, a particular number of members is selected from each age group to take a review of the book. These members are the final samples.
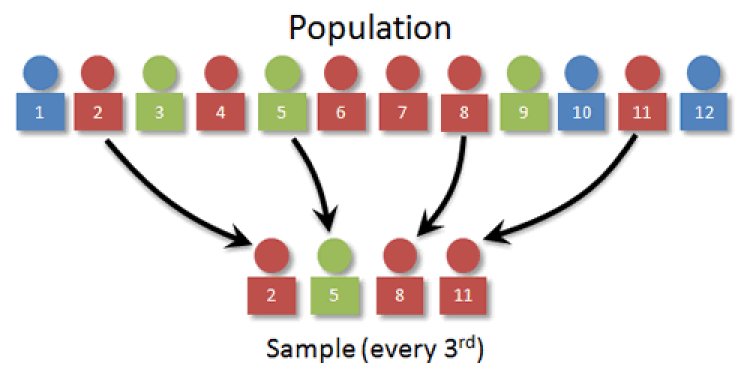
4. Systematic Sampling: In systematic sampling, every nth unit from the population is taken. That means a sample from the population is selected at every regular interval. The starting point is selected randomly and after that, every nth element is selected. In the below figure, n=3, so every 3rd element is selected.
5. Multi-stage sampling: If the selected samples are very large, then the researcher can again perform the sampling on the selected samples. This is known as multi-stage sampling.
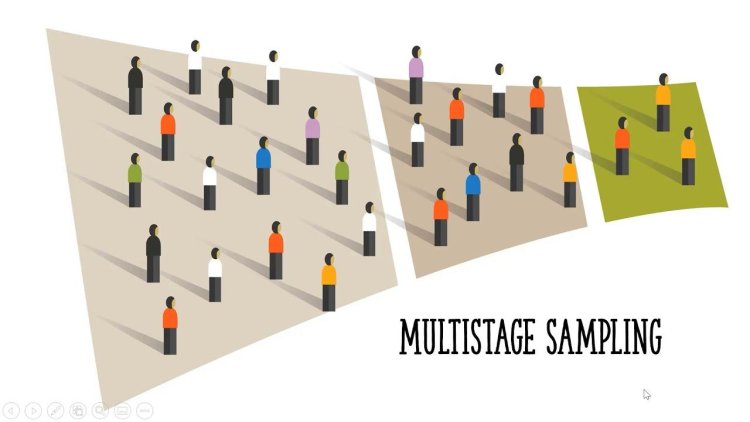
For example: After doing cluster sampling, if the sample size is very large, and then we can apply systematic sampling to select members according to to sample size.
Non-Probability Sampling: In non-probability sampling, all the units of the population have no probability of being selected as samples. This is a widely used sampling technique when cost and time is the main constraint.
Read this article to know: Python Tuples and When to Use them Over Lists
The types of Non-Probability Sampling are:
- Availability Sampling: This is also known as convenience sampling. This occurs when the researcher selects the samples based on availability. For example: If a student wants to do research on how many college students are using the canteen for lunch. He will select his own college and nearby colleges to do the survey.
- Judgmental Sampling: It is also called purposive sampling. In this samples are selected on basis of the researcher’s own knowledge, experience and intuition. The researcher selects this technique when they feel that other sampling techniques are time-consuming and he is confident about his knowledge.
- Quota Sampling: In this type of sampling, the researcher divides the population into some quotas according to some characteristic and select the members from each quota.
Also refer this article: 10 Common Data Structures Every Programmer Must Know
For Example: If a researcher wants to survey what cloth brand people prefer to choose. He can consider 600 samples. He can divide the population into the following quotas:
Age: 10-20, 20-30, 30-40, 40-50, 50-60 and 60+. He can take 100 samples from each quota.
Gender: Male-300 and female -300
Location: Take 100 samples from 6 locations.
- Snowball Sampling: This is also known as chain-referral sampling. In this, reference from existing samples is taken to collect the samples.
For Example: if a person is doing a survey on a rare disease and he knows only a few patients, then he can take the contacts of other persons from these patients and in this way, using snowball sampling, researchers can get in touch with these hard-to-contact sufferers.
Being a prominent data science institute, DataMites provides specialized training in topics including machine learning, deep learning, Python course, the internet of things. Our artificial intelligence at DataMites have been authorized by the International Association for Business Analytics Certification (IABAC), a body with a strong reputation and high appreciation in the analytics field.
Handling Imbalanced Datasets SMOTE Technique

What is SMOTE
