What is Cross-Validation and Validation in Machine Learning?
Cross-validation is a technique in machine learning used to assess model performance by splitting data into multiple training and testing sets. Validation helps tune model parameters by evaluating performance on a separate dataset before final testing.
Beginning with the Model:
Data science reaches one of its high points through the art of machine learning. The applications in predictive analytics and thereafter prescriptive analytics, are only growing in number. Machine learning offers several models for a data scientist to choose from. Model creation, however, involves the right use of preprocessed data. And here is where validation enters the picture.
The Idea of a Split:
To begin with, the archetypal data scientist will use a host of feature engineering techniques to arrive at the preprocessed data. Once that is done and we have zoned into the input features and the target output variable, it is a common practice to split the data into training and testing sets. Essentially, the split is a way to ensure that the model is being evaluated without any bias. For this purpose it is safe to make one assumption during the model creation: the segment of data used for testing the model should not have influenced the training phase whatsoever.
In Python, for example, data splitting is characterized by the train_test_split function in the sklearn library. This methodology works quite well up to a point. But the model does not always deliver when we get to the testing phase. And if the performance is found wanting, we need to fine-tune the model fitting process concerning the training dataset.
Refer to the article: What are Structured Data and Unstructured Data?
What is Validation?
To be clear, Hyper Parameter Tuning is nothing but a more extensively drawn-out phase of the model training, where we seek to run various parameters of the model in different combinations. The several iterations will then need to be evaluated. This is done to make sure we have optimal performance when the model eventually enters the testing stage.
Of course, we have the test data previously acquired from the data split. But as stated before, we will look to keep this test data miles away from any stage of the training phase viz. model evaluation at the time of tuning.
Therefore we have to contend with the only solution left: to partition the training data. While the majority of this dataset should be reserved for training, say about 20 to 30% may be utilized for evaluation purposes. This small chunk of data thus used for evaluation during tuning is called the validation dataset.
Validation as different from test data:
One can clear validation data is separate from the training data. We must also conclude in no uncertain terms: the validation set is entirely different from the test data. The distinction assumes particular relevance in light of the confusion among data scientists who tend to use test and validation as interchangeable terms.
Read this article: Support Vector Machine Algorithm (SVM) – Understanding Kernel Trick
Cross-Validation:
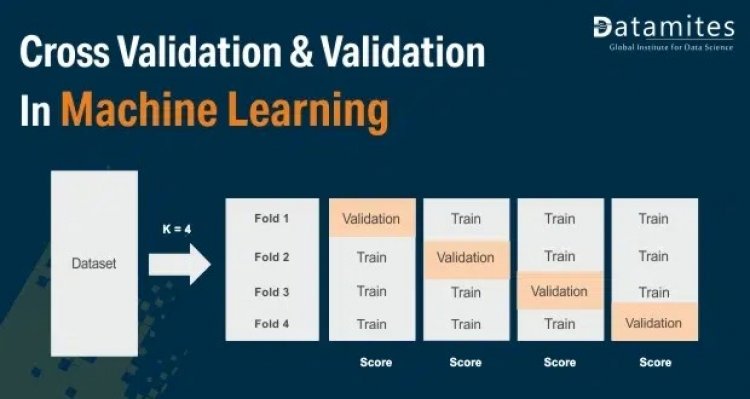
Cross-validation, as applied to machine learning models, is a shuffling or resampling technique used to check the model efficiency. The technique is more specifically called k-fold cross-validation. We will look to draw a picture of what the method is and what it does.
The notion of k folds looks to create k equal parts out of the shuffled training data. One part will be taken as a validation set and the remaining k-1 parts are utilized for training. The model is run and fit to the (k-1)-partly trained data. The model is then tested against the validation set and the score obtained is documented. The process now looks at each of the other assigned parts and holds it back from training, using it subsequently for validation purposes only.
Therefore the method is also called hold-out validation as each part is held back from training, turn by turn. It is common to take the value of k as 10. The value strikes the right balance between low bias and a not-so-high variance. Once a collection of model scores are available for the data we can take a mean of them to evaluate the model against the data. In certain parlance, these are also called skill scores. If the mean skill score is not quite satisfactory we can go back to the drawing board. But before that, it is a good idea to look at the standard error of these scores.
Also refer to the article: A Comprehensive Guide to K-Nearest Neighbor (KNN) Algorithm in Python
This methodology gives us ample room to measure the efficiency of the model.
What is Cross Validation

Cross validating can also be performed in a few variants. It could be repetitive, where the k-fold process repeats after shuffling the dataset thoroughly. Furthermore, stratified cross-validation, nested cross-validation, and leave-one-out are other types used within the framework of the fundamental technique.
Being a prominent data science institute, DataMites provides specialized training in topics including machine learning, deep learning, artificial intelligence, the internet of things, and python Courses. DataMites have been authorized by the International Association for Business Analytics Certification (IABAC), a body with a strong reputation and high appreciation in the analytics field.
DataMites Training Institute offers a globally accredited Machine Learning Course, recognized by IABAC and NASSCOM FutureSkills. Specializing in AI, Machine Learning, Data Science, Data Analytics, and Python Programming, DataMites provides hands-on experience through real-time internships, unlimited projects, and an exclusive practice lab. This immersive approach empowers students with the skills needed to excel in the ever-evolving tech industry.
What is Monte Carlo Simulation?
