What is Machine Learning & Types of ML Algorithms
Machine Learning is a branch of AI that enables computers to learn from data and make decisions without explicit programming. ML algorithms are categorized into Supervised, Unsupervised, and Reinforcement Learning, each serving different problem-solving needs.

Machine learning is a field of AI that includes specialized algorithms that learn through experiences. Here experiences are nothing but data. Data and corresponding output are fed to the algorithms. Subsequently, algorithms learn and make predictions.
Those predictions could be answering whether an animal in a photo is a cat or a dog, spotting people wearing masks and maintaining social distance on the streets of the city, whether your friend is rightly tagged on your social media platform, whether an email is spam, or whether an input sentence is rightly translated to a target language.
History of Machine Learning
One of the key reasons why we create (computer) programs is to automate different (often tedious) processes of different kinds. Machine learning was initially created as a subfield of Artificial Intelligence (AI), and one of the aims behind machine learning was to replace the need to “manually” design computer programs. In view of the development of programs to automate processes, we can think of machine learning as the “automation automation” process. In other words, machine learning helps computers to “create” programs (often, predictions are made in order to improve these programs) themselves. We may assume that the process of converting data into programs is machine learning. It is generally accepted in the machine learning community that the term machine learning was first coined in 1959 by Arthur Lee Samuel, an American IBMer, and pioneer in the field of computer gaming and artificial intelligence
One quote cited by almost every introductory machine learning resource is the following, which nicely and concisely summarizes the notion behind machine learning:
Machine learning is the field of study that gives computers the ability to learn without being explicitly programmed.
— Arthur L. Samuel, AI pioneer, 1959
The following figure summarizes the three broad categories of machine learning:
Types of ML algorithms
- Supervised learning
- Unsupervised learning
- Reinforcement learning

Supervised Learning
Supervised learning is the machine learning subcategory that focuses on learning a classification or regression model, i.e. learning from labeled training data (i.e. inputs that also include the desired outputs or goals; essentially, what we want to predict ‘examples’).
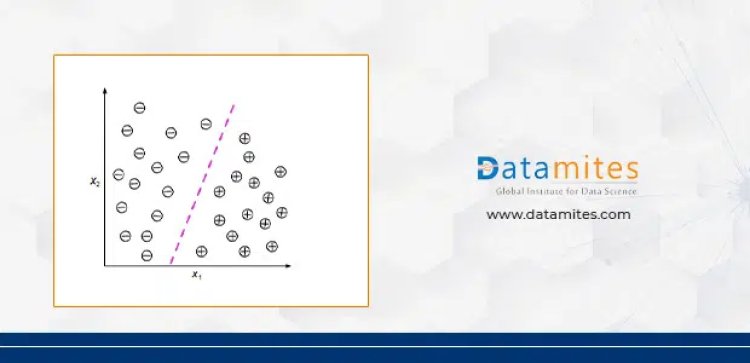
An example of binary classification is shown below( plus and minus indicates different classes)
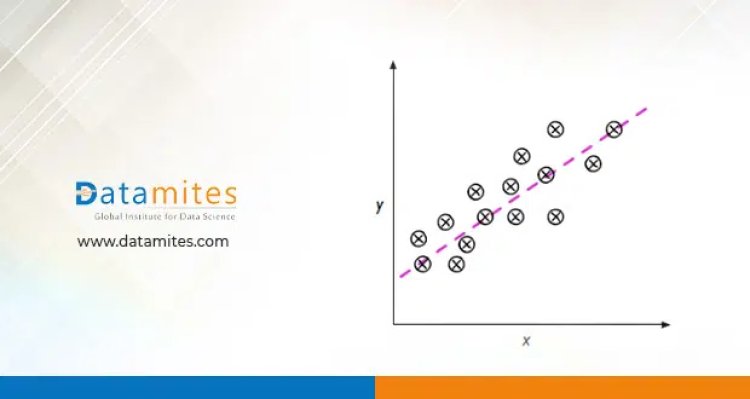
Example of a linear regression model with one feature variable (x) and the target variable y
Unsupervised Machine Learning
Unsupervised learning is a branch of machine learning that is concerned with unlabeled data, as opposed to supervised learning. A common task in unsupervised learning is clustering analysis.
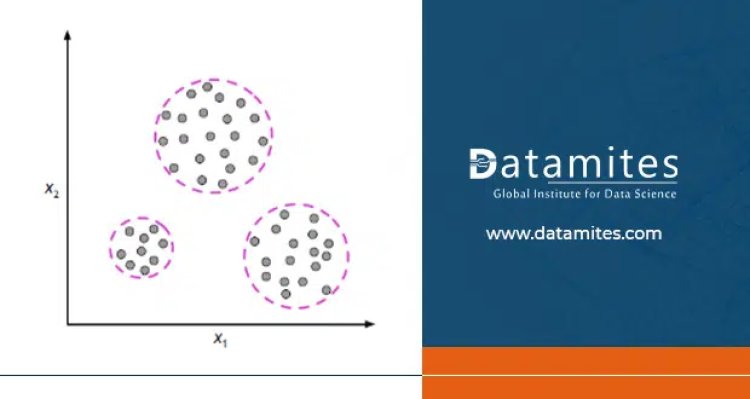
Illustration of clustering where possible group membership allocations of unlabeled data points are indicated by the dashed lines.
Reinforcement Learning
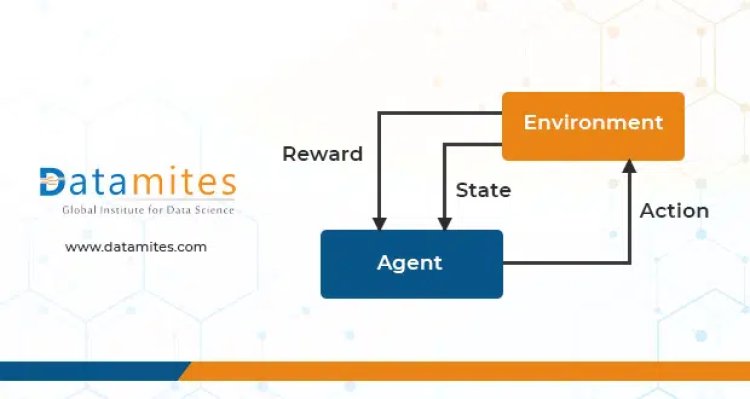
Reinforcement Learning is characterized as a method of machine learning that addresses how actions should be taken by software agents in an environment. Reinforcement Learning is an aspect of the system of deep learning that lets you optimize some portion of the accumulated reward.
Example: Self-driving cars is one the great examples of Reinforcement Learningd
R Programming vs Python Programming
Python and R are two of the most favored languages for data analysis. Most of the fresher’s get confused, whether they should use python or R to kickstart their.
| What is R? | What is Python? |
| R is a programming language made by statisticians and data Miners for statistical analysis and supported by the R foundation for statistical computing. | Python is a general-purpose, simple, object-oriented programming language that takes a general approach to data science. |
| The main objective of R is Data Analysis and Statistics | whereas the main objective of Python is Deployment and Production |
| Research Scholars and R&D are the main users of R | Python users are mostly Programmers and Developer |
| Some of the important packages of R are ggplot2, caret, zoo, tidyverse | Some of the essential packages of python are pandas, numpy, scikit learn |
| It is fast and easy to get primary results | It is good for machine learning model deployment |
| R studio is the IDE generally used | Python comes with different IDE such as Jupyter notebook, spider, |
| R runs locally | Python can be easily integrated with apps |
According to us, if you are a data science novice with a statistical background, you have two questions to ask yourself:
- Am I interested in understanding how the algorithm works?
- Do I want the trained model to be deployed?
If your answer is yes to both of the questions, you’d probably start learning Python first. Python, on the one hand, provides excellent libraries for matrix manipulation or algorithm coding. It may be easier to learn as a beginner how to construct a model from scratch and then move from the machine learning libraries to the functions. On the other hand, if you know the algorithm already, or you want to go into data analysis right away, then both R and Python are okay, to begin with.
Secondly, if you need to do more than numbers, like deployment and reproducibility, Python is more recommended. R is more apt for your work if you want to write a report and create a dashboard.
The statistical distance has become compact between the two languages, however. In the end, it’s your target you’re focused on and the most used tool for your business/organization.
Top ML Algorithms
If you are a Machine Learning or Data Science Enthusiastic. You must learn these important algorithms to create some functional projects.
- Linear Regression
- Naive Bayes Algorithm
- Decision Trees
- Random Forest
- XGBOOST

DataMites offers a globally accredited Machine Learning Course, covering core ML concepts, hands-on projects, and real-world applications. Expert-led training equips you with industry-ready skills in Python, AI, and deep learning, leading to a prestigious certification to advance your career in machine learning.