K-Nearest Neighbor (KNN) Algorithm in Machine Learning using Python
The K-Nearest Neighbor (KNN) algorithm is a simple yet powerful supervised learning technique used for classification and regression. This blog explores how KNN works, its implementation in Python, and real-world applications.
 Thushara C.P
Thushara C.P

K_nearest neighbor (KNN) is a supervised algorithm, that can solve both classification and regression tasks. Since it does not have a specialized training phase, it is called a lazy learning algorithm. It uses all the data for training while classifying a new data point.
Why do we need a K-NN Algorithm?
Let’s assume that we have two categories, Category A and Category B, & we have a new data point x1, so the question here is in which of these categories will the data point lie? To solve this kind of problem, we need a K-nearest neighbor algorithm. With the help of K-NN, the category or class of a particular dataset can be identified easily. Let’s consider the below figure:
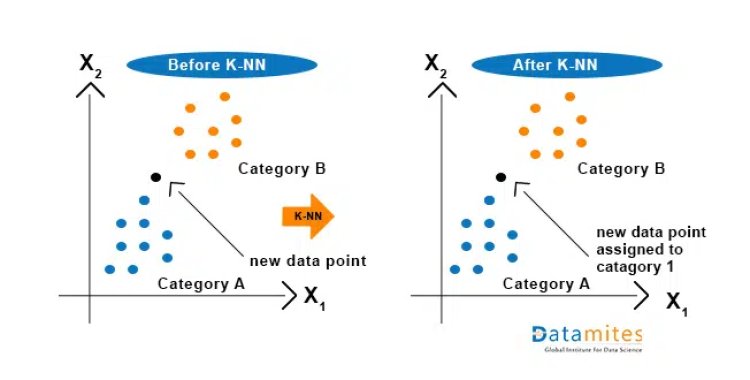
How does K-NN work?
The working of KNN for classification and regression.
K-NN for Classification
- Calculate the number of nearest neighbors.
- Calculate the distance of testing observations with all training data using Euclidean distance.
- Select 5 shortest distance observations from the testing point.
- Calculate the probability of all shortest observations.
- Assign testing observation with the highest priority.
Refer this article to know Support Vector Machine Algorithm (SVM) – Understanding Kernel Trick
K-NN for Regression
- Calculate the number of nearest neighbors.
- Calculate the distance of testing observations with all training data using Euclidean distance.
- Select 5 shortest distance observations from the testing point.
- Calculate the average distance of the nearest neighbor to testing observations.
- Assign average distance as the predicted value.
KNN Algorithm Explained | K- Nearest Neighbours | Machine Learning

How to select the value of K in the K-NN Algorithm?
The points to be remembered for selecting the value for K in KNN:
- To find the value of K we don’t have a specific predefined method.
- K value is initialized randomly & starts computing.
- If you choose a small value of K, the decision boundaries will be unstable.
- Derive a plot between error rate & K denoting values in a defined range.
- Then choose the value for K which has less error rate.
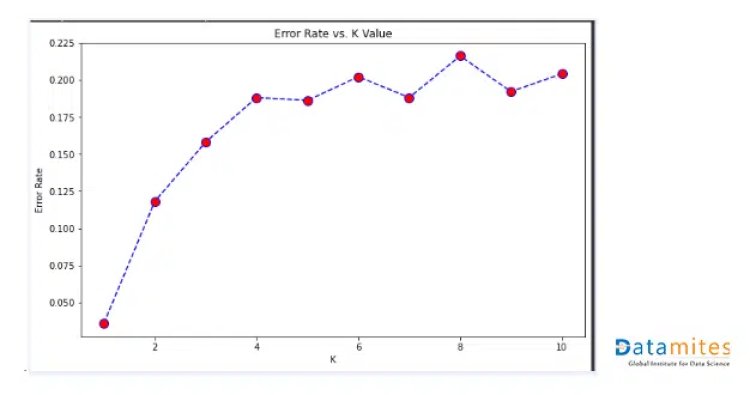
Take a look at the Pros and Cons of KNN:
Pros:
- The implementation is very easy.
- As said earlier, it is a lazy learning algorithm & therefore requires no training prior to making real-time predictions. This makes the KNN algorithm much faster than other algorithms that require training ex. SVM, linear regression, etc.
- New data can be added easily because the algorithm requires no training before making predictions.
- To implement KNN there are only two parameters.
- The math behind this algorithm is very easy to understand.
- Hyperparameter tuning is not required.
Cons:
- KNN does not work well with the large dataset, it will also not work well with high dimensions.
- It requires feature scaling (standardization and normalization).
- KNN is sensitive toward missing values and outliers.
- It requires lots of space because we need to store the whole training set for every test set.
Refer this article to know A Complete Guide to Naive Bayes Algorithm in Python
Distance measures on KNN
There are several distance measures techniques but wwe is only one among them.

Applications of KNN Algorithm
- Recommending systems: Recommending ads for youtube and social media users, recommending products on any E-commerce websites. For example, let’s say you buy a laptop from any E-commerce site, it recommends you to buy a portable mouse, keyboard, or laptop cover with it.
- KNN is used in politics whether the voter will vote or will not vote candidate.
- Other applications of KNN include video recognition, image recognition, and handwriting detection.
Python Implementation of KNN
Business Case:-To predicts whether a person will have diabetes or not.
Importing all required libraries
- import pandas as pd
- import numpy as np
- from sklearn.neighbors import KNeighborsClassifier
- from sklearn.neighbors import KNeighborsRegressor
- from sklearn.preprocessing import StandardScaler
- from sklearn.model_selection import train_test_split
- from sklearn.metrics import accuracy_score, confusion_matrix,classification_report
- import matplotlib.pyplot as plt
- import seaborn as sns
- import warnings
- warnings.filterwarnings(‘ignore’)
Measure purity of a node in Decision Tree Algorithm – Machine Learning

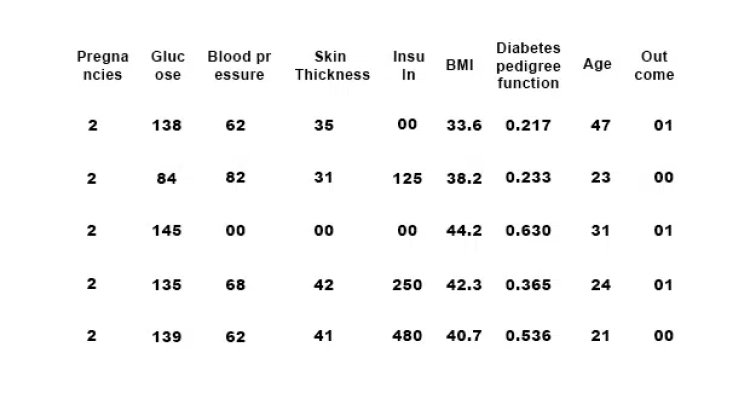
Reading the data
data = pd.read_csv(“diabetes.csv”)
data.head()
Output:
Get the insights from Exploratory Data Analysis
Check for missing values, categorical variables and outliers
Splitting X and y
X = data.drop(columns = [‘Outcome’]) # Independent variables
y = data[‘Outcome’] # Dependent or target variable.
Checking the balance of the target
sns.catplot(x=’Outcome’,data=data,kind=’count’) # Imbalanced dataset
Output:
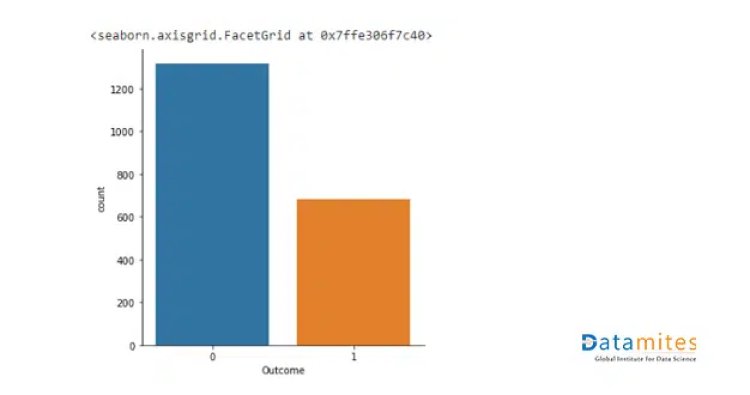
The above plot says that the output is an imbalance, now let’s see how to balance an imbalance data.
!pip install imblearn
#Apply SMOTE to balance the data
from imblearn.over_sampling import SMOTE
smote = SMOTE() ## object creation
X_train_smote, y_train_smote = smote.fit_resample(X_train.astype(‘float’),
y_train)
from collections import Counter
print(“Actual Classes”,Counter(y_train))
print(“SMOTE Classes”,Counter(y_train_smote))
Output:
Actual Classes Counter({0: 996, 1: 504})
SMOTE Classes Counter({0: 996, 1: 996})
Also read: A Guide to Principal Component Analysis (PCA) for Machine Learning
Scaling the data
scalar = StandardScaler()
X_scaled = scalar.fit_transform(X)
Splitting the training and the testing data
X_train,X_test,y_train,y_test=train_test_split(X_scaled,y,random_state=42)
Fitting the data into KNN model
knn1 = KNeighborsClassifier(n_neighbors=5)
knn1.fit(X_train,y_train)
Output: KNeighborsClassifier()
Predicting
y_pred = knn1.predict(X_test)
Evaluation
print(“The accuracy score is : “, accuracy_score(y_test,y_pred))
Output: The accuracy score is : 0.814
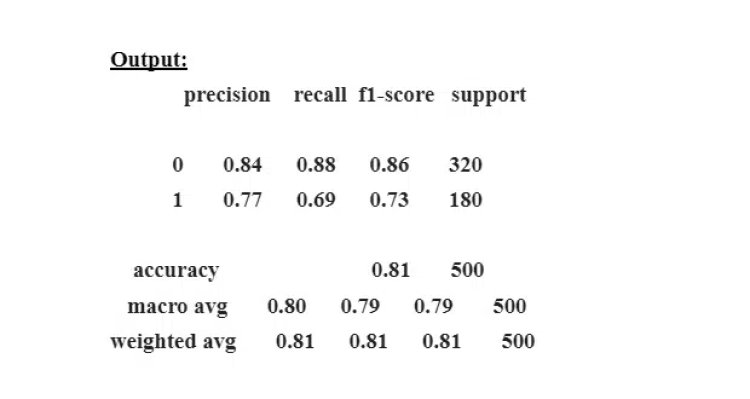
print(classification_report(y_test,y_pred))
Being a prominent data science institute, DataMites provides specialised training in topics including Python, machine learning, artificial intelligence, the internet of things, and deep learning. Our Machine Learning Courses at DataMites have been authorised by the International Association for Business Analytics Certification (IABAC), a body with a strong reputation and high appreciation in the analytics field.
The DataMites Machine Learning course provides expert-level training in AI-driven data analysis, enabling computers to learn from experience and execute tasks without explicit programming. Accredited by IABAC and NASSCOM FutureSkills, DataMites is a leading institute in Machine Learning and AI education. With over a decade of experience, it has empowered more than 100,000 learners globally.
Types of Machine Learning
