Getting Started with Machine Learning: A Beginner’s Guide
This beginner’s guide to machine learning introduces core concepts and practical steps to kickstart your journey in AI. Learn the essential tools and techniques to build a strong foundation in machine learning.

Machine learning is revolutionizing industries, from healthcare to finance, transforming how we make decisions and automate tasks. Did you know that according to Forbes, by 2025, the global machine learning market is expected to grow to $9 billion? This significant growth highlights the crucial importance of machine learning skills in the current job market.
This guide aims to equip you with the essential knowledge needed to understand and begin your journey into machine learning. By the end of this guide, you will have a clear understanding of what machine learning is, the prerequisites needed to learn it, and the steps involved in building and deploying machine learning models.
Understanding Machine Learning
What is Machine Learning?
Machine learning (ML) is a branch of artificial intelligence (AI) that centers on developing systems capable of learning from data and making decisions accordingly. Unlike traditional programming, where a programmer writes explicit instructions, machine learning models identify patterns and make predictions from the data provided.
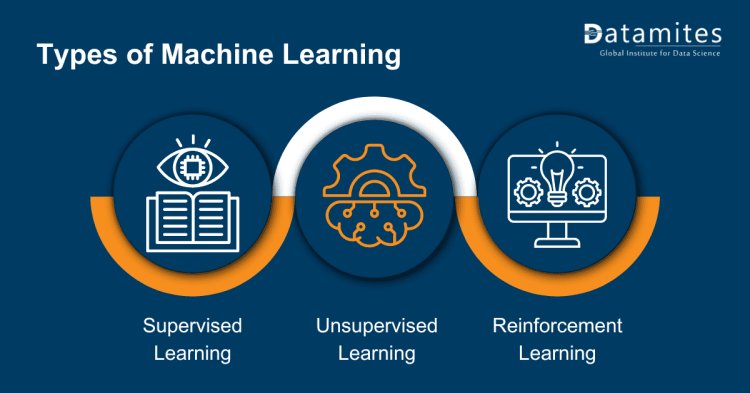
Types of Machine Learning
Supervised Learning: This involves training a model using labeled data, allowing it to learn how to make predictions or decisions based on the provided dataset. For example, predicting house prices based on historical data.
Unsupervised Learning: In this scenario, the model is trained on data that isn’t labeled and is tasked with identifying patterns or structures on its own. Clustering and association are common techniques used in unsupervised learning.
Reinforcement Learning: This type of learning involves an agent that learns by interacting with its environment and receiving rewards or penalties. It’s widely used in game playing, robotics, and self-driving cars.
Refer these articles:
- Guide to Machine Learning Career
- Deep Learning vs Machine Learning
- Artificial Intelligence vs Machine Learning
Top Machine Learning Algorithms You Should Know
Here are some of the top machine learning algorithms widely used in the industry:
- Linear Regression: Used for predicting a continuous variable based on the relationship between the dependent and independent variables.
- Logistic Regression: Used for binary classification tasks, predicting the likelihood of a binary outcome.
- Decision Trees: A tree-like model used for classification and regression tasks, where decisions are made based on the features of the data.
- Random Forests: An ensemble technique that leverages several decision trees to enhance the accuracy and reliability of the model.
- Support Vector Machines (SVM): A classification algorithm that finds the optimal hyperplane to separate different classes in the feature space.
- K-Nearest Neighbors (KNN): A simple, instance-based learning algorithm used for both classification and regression, where the output is determined by the majority vote or average of the k-nearest neighbors.

Essential Foundations for Mastering Machine Learning
When starting with machine learning, having a solid foundation in certain areas can greatly enhance your learning experience and understanding. Here are the key prerequisites:
Mathematical Foundations
A solid understanding of mathematics is essential for grasping machine learning concepts. Key areas include:
Linear Algebra:
- Vectors and Matrices: These are fundamental building blocks in machine learning. They are used to represent data and perform various operations.
- Operations: Grasping operations like matrix multiplication, vector addition, and transformations is essential. These operations are at the core of many machine learning algorithms and help in representing and processing data efficiently.
Calculus:
- Derivatives: Derivatives play a crucial role in optimization algorithms, which are fundamental for training machine learning models. They help in understanding how the model's parameters change with respect to the loss function.
- Integrals: While less frequently used than derivatives, integrals are important for understanding areas under curves and cumulative changes, which can be relevant in certain algorithms and applications.
Probability and Statistics:
- Basic Concepts: Key concepts include probability distributions, mean, variance, and standard deviation. These are crucial for making predictions and understanding the variability in data.
- Distributions: Familiarity with normal, binomial, and other distributions is important as they frequently appear in machine learning tasks. Understanding these distributions helps in modeling the uncertainty and variability in data.
Programming Skills
Programming is a fundamental skill for implementing and experimenting with machine learning algorithms.
Importance of Programming in ML: Writing code allows you to implement, test, and refine machine learning models. It also helps in automating data processing and analysis tasks.
Recommended Programming Languages:
- Python: Python is the most popular language for machine learning due to its readability, ease of use, and extensive library support.
- R: R is another powerful language, especially for statistical analysis and creating visualizations.
Computer Science Fundamentals
A good grasp of computer science principles is essential for efficiently implementing and optimizing machine learning models.
Data Structures and Algorithms:
- Data Structures: Understanding lists, arrays, trees, and graphs is crucial. These structures assist in the efficient organization and management of data.
- Algorithms: Knowledge of sorting, searching, and graph algorithms is important for processing and analyzing data effectively.
Understanding of Databases and SQL:
- Knowledge of Databases: Being able to manage and query data efficiently is crucial in machine learning. Understanding database concepts helps in storing, retrieving, and manipulating large datasets.
- SQL: Proficiency in SQL is essential for data retrieval and manipulation. SQL is commonly used to query databases and extract data for analysis.
By mastering these prerequisites, you'll be well-equipped to delve into the field of machine learning and tackle its challenges effectively.
The Machine Learning Process
Machine learning (ML) is a fascinating field that enables computers to learn from data and make decisions or predictions. The ML process can be complex, but breaking it down into manageable steps can make it more understandable. Here is a simplified guide to the machine learning process:
1. Data Collection
Sources of Data: Data can be gathered from various sources such as:
- Public Datasets: Available from organizations and universities, these datasets provide a wealth of information for training and testing models. Examples include the UCI Machine Learning Repository and Kaggle datasets.
- APIs: Allowing access to data from web services, APIs enable the retrieval of real-time data from sources like social media platforms, financial markets, and weather services.
- Company Databases: Internal data sources stored within an organization’s databases provide proprietary data that can be crucial for business-specific applications.
Importance of Quality Data: The success of machine learning models heavily depends on the quality and quantity of the data. High-quality data ensures accurate and reliable model predictions, while large volumes of data enable the model to capture complex patterns and relationships.
2. Data Preprocessing
Cleaning and Preparing Data: Essential steps include removing duplicates, correcting errors, and standardizing formats to ensure the data is clean and usable for analysis.
- Removing Duplicates: Ensures that redundant data does not bias the model.
- Correcting Errors: Involves identifying and fixing inaccuracies in the data.
- Standardizing Formats: Converts data into a consistent format to facilitate seamless analysis.
Handling Missing Values: Techniques like imputation (filling missing values with statistical measures) or removal (excluding rows or columns with missing data) are used to handle incomplete data.
- Imputation: Filling in missing values with mean, median, mode, or using algorithms to predict missing values.
- Removal: Discarding records with missing values if they constitute a small percentage of the dataset.
Handling Outliers: Identifying and managing unusual data points that can skew model performance. Techniques include:
- Z-Score Analysis: Identifying outliers based on their distance from the mean.
- IQR Method: Using the interquartile range to detect outliers.
Feature Engineering: Generating new features from existing data to enhance model performance. This can involve:
- Transformation: Applying mathematical functions to existing features.
- Combination: Combining multiple features to create new ones.
- Decomposition: Breaking down complex features into simpler components.
3. Model Selection
When choosing a machine learning model, consider the problem type, data size, and computational efficiency. For predicting continuous values, Linear Regression is ideal due to its simplicity and interpretability, as it directly links input features to target values. Decision Trees are versatile for both classification and regression, offering clear, visual decision-making processes. K-Nearest Neighbors (KNN) is effective for classification tasks, determining the label of a new data point based on the majority label of its nearest neighbors, which is useful when proximity-based classification is advantageous.
4. Training the Model
Splitting Data into Training and Testing Sets: Ensures the model's performance is evaluated on unseen data, preventing overfitting and ensuring generalization.
- Training Set: Used to train the model.
- Testing Set: Used to assess the model's effectiveness.
Training Procedures: Techniques like cross-validation to improve model reliability. Cross-validation involves splitting the data into multiple folds and training the model on each fold to ensure robust performance.
- K-Fold Cross-Validation: Divides the data into k subsets, training the model k times, each time using a different subset as the testing set and the remaining as the training set.
5. Evaluation
Metrics for Model Evaluation: Various metrics help assess the model's performance.
- Accuracy: The proportion of correctly predicted instances compared to the total number of instances. This measure is especially useful for datasets with balanced classes.
- Precision: The ratio of correctly predicted positive instances to the total number of instances predicted as positive. This metric is crucial when the cost of false positives is significant.
- Recall: The ratio of correctly predicted positive outcomes to the total number of actual positive cases. This measure is especially important when the cost of missing true positives is high.
- Mean Squared Error (MSE): For regression tasks, it measures the average squared difference between the predicted and actual values.
Cross-Validation Techniques: Methods like k-fold cross-validation to ensure the model generalizes well. This technique helps in verifying that the model performs well on different subsets of data.
6. Deployment
Introduction to Deploying Models: After training and evaluating, the next step is to deploy the model. Deployment involves making the model available for use in real-world applications.
Basic Steps:
- Exporting the Model: Saving the trained model in a format that can be used for deployment (e.g., a pickle file in Python).
- Setting Up an API: Creating an API to allow other applications to interact with the model. Frameworks like Flask can be used to build RESTful APIs.
- Integrating into Applications: Embedding the model into web or mobile applications to provide predictive functionalities.
Tools for Deployment:
- Docker: A platform for containerizing applications, ensuring they run consistently across different environments.
- Flask: A lightweight web framework for Python, useful for setting up APIs to serve machine learning models.
- Cloud Platforms: Services like AWS, Google Cloud, and Azure provide scalable infrastructure and tools for deploying and managing machine learning models.
Refer these articles:
- What is Certified Python Developer?
- What Is AI Engineer Course?
- What is Certified Data Scientist Course?
Tools and Libraries for Machine Learning
Numerous critical tools and libraries are commonly utilized in machine learning (ML) projects. Here are some of the most well-known ones:
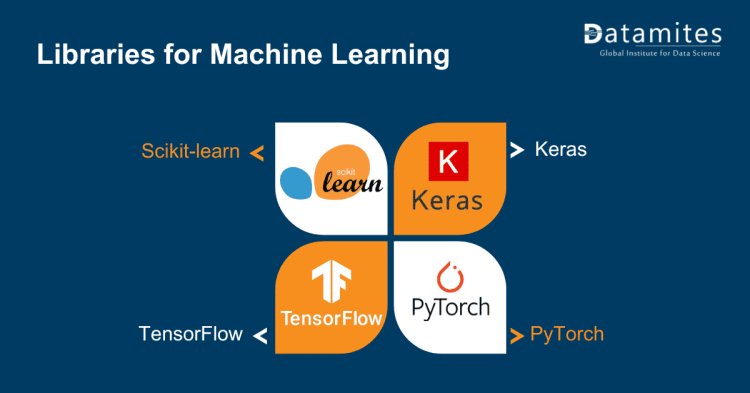
Popular ML Libraries
- Scikit-learn: Renowned for its straightforwardness and effectiveness, Scikit-learn is a popular choice for traditional machine learning tasks like classification, regression, and clustering.
- TensorFlow: Developed by Google, TensorFlow is a powerful framework for building and training deep learning models. It accommodates both high-level APIs such as Keras and low-level operations, offering maximum flexibility.
- PyTorch: Created by Facebook's AI Research lab (FAIR), PyTorch stands out for its dynamic computational graph, earning acclaim from both researchers and practitioners for its user-friendly and adaptable nature.
- Keras: Initially developed as a high-level API for TensorFlow, Keras now supports multiple backends including TensorFlow, Theano, and CNTK. It simplifies the process of building neural networks and is often the choice for beginners due to its user-friendly interface.
Integrated Development Environments (IDEs)
- Jupyter Notebook: A widely-used tool for interactive data science and machine learning exploration. It lets you craft and distribute documents featuring interactive code, mathematical formulas, visualizations, and descriptive text.
- Google Colab: A cloud-based Jupyter notebook environment provided by Google Research. It offers free GPU and TPU (Tensor Processing Unit) access, making it ideal for training deep learning models without requiring powerful local hardware.
- VS Code (Visual Studio Code): A lightweight yet powerful code editor developed by Microsoft. It supports various programming languages and has extensions that enable functionality for machine learning, including debugging, linting, and version control integration.
These tools and libraries provide a robust ecosystem for developing, experimenting with, and deploying machine learning models across various domains and applications.
Challenges in Machine Learning
Machine learning encounters numerous obstacles that both researchers and practitioners are constantly striving to overcome. Here are some key challenges:
Data Quality and Quantity:
- Data Availability: Acquiring sufficient data is challenging, especially in specialized domains where data collection is limited or expensive.
- Data Quality Issues: Inaccurate models can result from data of poor quality. Cleaning and preprocessing are crucial to ensure quality.
Bias and Fairness:
- Ethical Considerations: Ensuring data and models do not perpetuate biases to avoid discrimination in automated decision-making.
- Bias Mitigation Techniques: Using data augmentation, fairness-aware algorithms, and regular audits to detect and mitigate biases.
Computational Resources:
- High Computational Power: Training complex models requires powerful hardware like GPUs or TPUs.
- Infrastructure Needs: Maintaining infrastructure for large-scale data processing and model training often requires cloud platforms or dedicated servers.
These challenges emphasize the need for technical proficiency in data handling, bias understanding, and computational resource management for successful model development and deployment.
Read these articles:
Global Salaries for Machine Learning Engineers
Machine learning engineers are among the highest-paid professionals globally, reflecting their vital role in the tech industry. The growing demand for expertise in artificial intelligence and data science has significantly increased their salaries. Companies highly value their ability to develop advanced algorithms and solutions, offering attractive compensation packages to attract and retain top talent in this fast-changing field.
- United States: Machine Learning Engineers earn a median annual salary of $161,260, according to Indeed.
- United Kingdom: According to Indeed, Machine Learning Engineers earn an average annual salary of £63,682.
- India: According to Indeed, Machine Learning Engineers in India earn an average annual salary of ₹10,20,374.
- Canada: Indeed notes that the average salary for a Machine Learning Engineer in Canada is CAD 106,987 per year.
- South Africa: Indeed reports that the average annual salary for a Machine Learning Engineer in South Africa is ZAR 680,209.
- United Arab Emirates (UAE): According to Indeed, Machine Learning Engineers in the UAE earn an average annual salary of AED 142,516.
Machine learning stands at the forefront of technological innovation, reshaping industries across the globe. This guide has offered a thorough introduction, catering especially to beginners, by delving into fundamental concepts, prerequisites, the iterative ML process, and essential tools. To embark on this transformative journey, consider exploring machine learning certifications. These resources not only build a robust knowledge base but also equip you with the skills needed to navigate and contribute to this exciting field. Whether you're driven by curiosity or aiming to make an impact, embracing machine learning promises a rewarding path ahead.
DataMites Institute offers comprehensive training in Artificial Intelligence and Machine Learning, accredited by IABAC and NASSCOM FutureSkills. The courses include real-world projects and internship opportunities, ensuring practical learning experiences. The Machine Learning course covers Python programming, computer vision, natural language processing (NLP), and other key areas of AI. Similarly, the Artificial Intelligence course delves into advanced topics such as Generative Adversarial Networks (GANs) and more.
DataMites Training Institute offers an extensive Machine Learning Course, accredited by global certification bodies like IABAC and NASSCOM FutureSkills. With a focus on AI, Machine Learning, Data Science, Data Analytics, and Python Programming, students gain practical experience through real-time internships, unlimited projects, and an exclusive practice lab. This hands-on learning ensures students are well-prepared to excel in the fast-paced tech industry.
DataMites Institute offers classroom training in key cities such as Bangalore, Hyderabad, Mumbai, Chennai, Pune, and Ahmedabad, ensuring convenient access to education. Their programs, led by industry experts, provide hands-on learning opportunities designed to enhance AI skills and explore practical applications in machine learning. This structured approach equips students for various career prospects in today's AI-focused landscape.