How Gradient Boosting Works in Machine Learning
Explore how gradient boosting works in machine learning, its key concepts, advantages, and real-world applications for improving predictive model performance.

Machine learning has revolutionized industries with its ability to analyze data, identify patterns, and make accurate predictions. Among the various machine learning algorithms, Gradient Boosting has emerged as one of the most powerful and widely used techniques for classification, regression, and ranking tasks. From powering recommendation systems to detecting fraud in banking, Gradient Boosting has proven its effectiveness in solving complex problems with high accuracy.
In this article, we will break down how Gradient Boosting works in machine learning, explore its core concepts, and look into its real-world applications.
Basics of Boosting
Before diving into gradient boosting, it’s important to understand boosting. Boosting is an ensemble learning technique that combines multiple weak learners (typically decision trees) to form a strong predictive model.
- A weak learner is a model that performs slightly better than random guessing.
- Boosting improves accuracy by training models sequentially, where each new model corrects the errors of the previous one.
The iterative nature of boosting algorithms makes them highly effective in handling complex data challenges. With the power of AI in businesses can now predict equipment failures with up to 80% accuracy, significantly minimizing downtime and improving operational efficiency.
Core Concept of Gradient Boosting
Gradient Boosting extends the fundamental idea of boosting but takes it one step further by leveraging gradient descent optimization to systematically reduce errors. Instead of simply combining weak learners, it builds models in a stage-wise manner and refines predictions by minimizing a predefined loss function.
Here’s a detailed breakdown of how Gradient Boosting works:
Initial Prediction
- The process begins with a very simple model, often called the base model.
- In regression problems, this is usually the mean of the target values, while in classification problems it may be the log odds of the classes.
- This serves as a baseline for further improvements.
Compute Residuals (Errors)
- After the first prediction, the algorithm calculates the difference between the actual values and the predicted values.
- These differences, known as residuals, indicate where the model is making mistakes and provide insights into how the next model should adjust.
Train Weak Learners on Residuals
- A new decision tree (usually a shallow one with limited depth) is trained specifically to predict the residuals instead of the actual target values.
- By focusing on the residuals, the tree learns the parts of the data that the previous model couldn’t capture.
Update Predictions
- The predictions from the new tree are combined with the existing model using a learning rate (also known as shrinkage).
- The learning rate controls how much influence each new tree has. A smaller rate leads to slower but more accurate learning, whereas a higher rate speeds up training but may risk overfitting.
Iterative Process
- This process repeats over many iterations, with each new tree trying to correct the errors of the previous ensemble.
- Over time, the model becomes increasingly accurate as it systematically reduces the residuals.
Minimizing a Loss Function
- At the core of Gradient Boosting lies a loss function that measures how far predictions are from the actual values.
- For regression, common loss functions include Mean Squared Error (MSE) or Mean Absolute Error (MAE).
- For classification, algorithms often use Log Loss or Cross-Entropy Loss.
- Gradient descent optimization ensures that each iteration moves the model closer to minimizing this loss, leading to better performance.
In essence, Gradient Boosting doesn’t just train trees, it optimizes the entire learning process by following the gradient of the loss function. This makes it far more powerful and accurate compared to traditional boosting techniques.
Refer these below articles:
- Generative AI and Predictive AI: Key Differences Explained
- Why Artificial Intelligence Matters More Than Ever
- How Artificial Intelligence is Transforming Digital Marketing
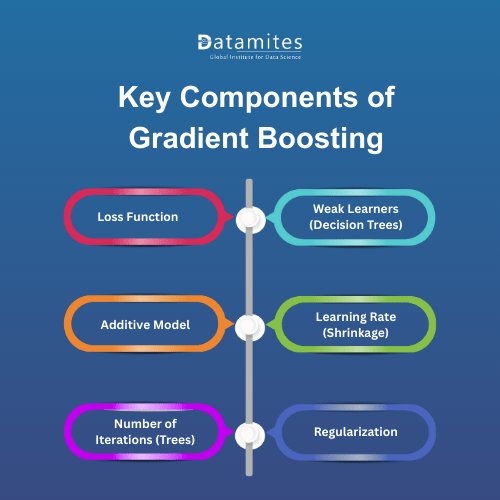
Key Components of Gradient Boosting
To truly understand how Gradient Boosting works in machine learning, it’s essential to explore the key components that make the algorithm both powerful and flexible. Each of these elements plays a vital role in shaping the performance of the model.
1. Loss Function
The loss function defines how the errors between predicted and actual values are measured. It acts as a guide for the algorithm, helping it understand where it is going wrong and how much correction is needed in the next step.
- Regression tasks often use Mean Squared Error (MSE) or Mean Absolute Error (MAE).
- Classification tasks commonly rely on Log Loss or Cross-Entropy Loss.
- Custom loss functions can also be defined depending on the problem.
Without a loss function, the model would have no direction in minimizing errors and improving accuracy.
2. Weak Learners (Decision Trees)
The backbone of Gradient Boosting lies in weak learners, typically decision trees with limited depth (often called “stumps”).
- These shallow trees are not strong on their own, but when combined sequentially, they form a highly accurate predictive model.
- Each tree focuses on correcting the residuals (errors) left by the previous trees.
- By keeping the trees shallow, the model avoids overfitting and maintains generalization ability.
3. Additive Model
Gradient Boosting uses an additive learning strategy, meaning new trees are added one at a time to improve the overall model.
- Instead of replacing old predictions, each new tree adds to the existing ensemble.
- This gradual, step-by-step improvement helps refine predictions without making drastic changes that could destabilize the model.
4. Learning Rate (Shrinkage)
The learning rate controls how much influence each new tree has on the final prediction.
- A small learning rate (e.g., 0.01 or 0.1) means each tree contributes only a little, requiring more iterations but often leading to better generalization.
- A large learning rate speeds up learning but risks overshooting and overfitting.
- Finding the right balance between learning rate and the number of iterations is crucial for optimal performance.
5. Number of Iterations (Trees)
The number of iterations determines how many trees are added to the model.
- Too few trees → The model underfits and fails to capture important patterns.
- Too many trees → The model overfits, memorizing training data instead of learning generalizable patterns.
- Cross-validation is often used to find the ideal number of trees for a dataset.
6. Regularization
To prevent overfitting, Gradient Boosting employs regularization techniques such as:
- Limiting tree depth → Controls the complexity of each tree.
- L1 and L2 regularization → Adds penalties to the model’s weights, similar to techniques in linear models.
- Subsampling (Stochastic Gradient Boosting) → Uses only a random subset of data for each tree, introducing randomness that enhances generalization.
By leveraging these techniques, Gradient Boosting achieves an optimal balance between accuracy and robustness, enabling AI systems to detect fraudulent transactions with up to 99% accuracy.
Popular Implementations of Gradient Boosting
Over the years, several optimized implementations of Gradient Boosting have been developed to address challenges like training speed, memory usage, and handling large-scale datasets. These libraries are widely adopted in both research and industry because they provide efficient, ready-to-use frameworks that make Gradient Boosting more practical and powerful.
Let’s explore the most popular ones:
1. XGBoost (Extreme Gradient Boosting)
Why it’s popular: XGBoost is one of the most widely used Gradient Boosting libraries, especially known for its exceptional speed and accuracy. It became famous through its dominance in Kaggle competitions and data science challenges.
Key features:
- Uses advanced regularization (L1 & L2) to control overfitting.
- Optimized for parallel processing, making it faster than traditional implementations.
- Can handle missing values automatically during training.
Best for: Competitive machine learning projects and high-stakes predictive modeling.
2. LightGBM (Light Gradient Boosting Machine)
Why it stands out: Developed by Microsoft, LightGBM is designed for high efficiency and scalability, especially with large datasets.
Key features:
- Uses a novel leaf-wise tree growth strategy that improves accuracy.
- Supports GPU acceleration for faster training.
- Handles categorical features using a special technique called Gradient-based One-Side Sampling (GOSS).
Best for: Big data applications where speed and memory efficiency are critical.
3. CatBoost
Why it’s unique: Created by Yandex, CatBoost specializes in handling categorical variables automatically, reducing the need for extensive preprocessing.
Key features:
- Eliminates the need for one-hot encoding, saving time and reducing dimensionality.
- Provides excellent performance with minimal hyperparameter tuning.
- Has strong support for both classification and ranking problems.
Best for: Datasets with many categorical features, such as customer data or e-commerce platforms.
4. Scikit-learn’s GradientBoosting
Why it’s beginner-friendly: The Scikit-learn library includes a simple Gradient Boosting implementation that is easy to use for newcomers.
Key features:
- Seamless integration with the Scikit-learn ecosystem.
- Ideal for learning and experimenting with smaller datasets.
- Supports both regression and classification tasks.
Best for: Students, beginners, and small-scale projects that prioritize ease of use over speed.
All major implementations of Gradient Boosting such as XGBoost, LightGBM, CatBoost, and Scikit-learn are built on the same core principle of sequentially boosting weak learners. According to Grand View Research, the global wearable AI market was valued at USD 26,879.9 million in 2023 and is expected to grow to USD 166,468.3 million by 2030, registering a CAGR of 29.8% between 2024 and 2030.
Read these below articles:
Real-World Applications of Gradient Boosting
Gradient Boosting is not just a theoretical concept it powers many technologies that we rely on in our daily lives. Its ability to provide high predictive accuracy makes it a preferred choice in industries where precision is critical. Here are some notable real-world applications:
1. Finance & Banking: Fraud detection systems extensively use Gradient Boosting to identify unusual transaction patterns and prevent financial losses. Over 70% of banks worldwide are now implementing AI-based fraud detection systems.
2. Healthcare: Gradient Boosting helps in disease prediction, medical diagnosis, and patient risk assessment. Studies show that approximately 60% of healthcare organizations have integrated AI solutions into their operations, enhancing patient outcomes and reducing errors.
3. E-commerce & Retail: Personalized recommendation engines in e-commerce platforms leverage Gradient Boosting to suggest products based on user behavior. Reports indicate that 35% of online purchases are influenced by AI-driven recommendations.
4. Marketing & Customer Analytics: Businesses use Gradient Boosting to predict customer churn, optimize marketing campaigns, and segment audiences effectively. Up to 57% of marketers rely on AI analytics to improve customer engagement strategies.
5. Transportation & Logistics: Gradient Boosting improves demand forecasting, route optimization, and predictive maintenance of vehicles, reducing operational costs. A report shows that AI-driven logistics solutions can increase delivery efficiency by up to 30%.
6. Cybersecurity: In cybersecurity, Gradient Boosting detects suspicious activities and prevents potential threats by analyzing large-scale data patterns. Reports indicate that over 40% of cybersecurity solutions now incorporate AI-based threat detection models.
By delivering accurate and reliable predictions, Gradient Boosting has become the go-to algorithm across industries that demand precision and efficiency. Its versatility from finance and healthcare to retail and cybersecurity highlights why mastering this algorithm is essential for modern data-driven applications.
Gradient boosting is one of the most powerful techniques in machine learning, combining the strengths of boosting with gradient-based optimization. By sequentially correcting errors, leveraging weak learners, and optimizing through gradients, it delivers outstanding performance in both classification and regression problems.
AI is driving transformation across IT, healthcare, finance, education, transportation, and startups in Hyderabad. By boosting efficiency, decision-making, and innovation, the city is emerging as a leading AI hub in India. For students and professionals, pursuing an Artificial Intelligence course in Hyderabad offers valuable career opportunities in AI, machine learning, and data science.
DataMites Artificial Intelligence Institute in Bangalore provides a comprehensive learning experience designed for both beginners and working professionals. With expert-led training, globally recognized certifications, and dedicated career support, DataMites Bangalore equips students to thrive in India’s leading tech hub.