A Complete Guide to XGBOOST Algorithm in Python

Created by Tianqi Chen, XGBoost or Extreme Gradient Boosting emerges as the obvious choice when it comes to a superfast machine learning algorithm that operates on tree-based models and attempts to achieve the best in class accuracy by optimally employing CPU resources. It has gained a lot of attention due to its widespread use in hackathons and Kaggle events. It may be officially defined as a decision tree-based ensemble learning framework that uses Gradient Descent as the underlying objective function, offers a great deal of flexibility, and efficiently utilises computing power to produce the required results.
XGBoost, An Ensemble technique?
The boosting family of algorithms, which includes XGBoost, is a component of the ensemble learning approach. The next logical inquiry is, “What is ensemble learning?” The term “ensemble” denotes a band of musicians, as we highlighted within one of our former postings. Taking a cue from that, ensemble learning in the context of machine learning is simply knowledge acquired through teamwork. Ensemble learning is the process of merging numerous models to provide predictions that perform better than the results of a single model.
XGBOOST in Python

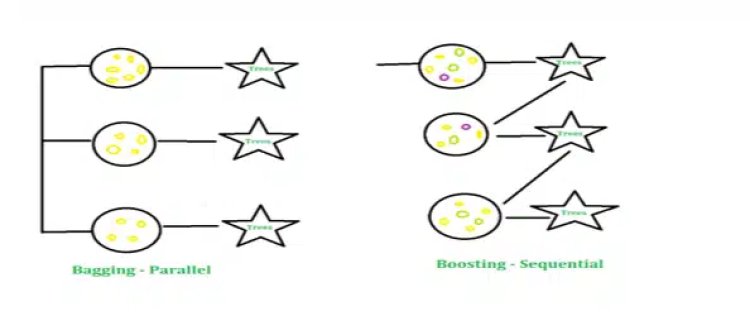
What is Bagging and Boosting?
Bagging: When lowering a base learner’s variance is our goal, bagging is used. Here, the idea is to divide the training sample, which is selected at random with replacement, into a few smaller data sets. We now have an ensemble of different models as each collection of subset data is used to create its model. It is more effective than using just one model to use the average of all the assumptions from many models.
Boosting: Another ensemble method to create a group of predictors is boosting. In other words, we fit a series of weak learners, often drawn from random samples, with the goal of resolving the net error introduced by the earlier weak learner at each stage. By consolidating the complete set, weak learners are finally transformed into better-performing models whenever a certain input is misclassified by theory. This increases the weight of the input so that the subsequent hypothesis is more likely to categorize the input properly.
Bagging – Data Science Terminologies

Read this article: A Complete Guide to Logistic Regression Algorithm in Python
What are the advantages of using XGBoost over other algorithms?
- Number of hyperparameters to tune
- Computationally efficient by using parallel and distributed computing
- Ability to handle missing and sparse data
Python Implementation:
We will import the Boston dataset from sci-kit learn.
The implementation is quite straightforward, as the pipeline follows the same structure as for the remaining machine learning models.
Importing all necessary libraries.
import pandas as pd
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score,mean_squared_error
from xgboost import XGBRegressor
import warnings
warnings.filterwarnings(‘ignore’)
Loading, splitting and training the Boston house dataset.
boston = load_boston()
X,y = boston.data,boston.target
X_train,X_test,y_train,y_test = train_test_split(X,y)
xgboost = XGBRegressor()
xgboost.fit(X_train,y_train)
Predicting the output and computing mean square error
test_pred = xgboost.predict(X_test)
mean_squared_error(y_test,test_pred)
The mean squared error came to be 14.388. The main aspect of any machine learning model relies on its parameters. A hyper-parameter is a parameter external to the model that is set manually before the learning process happens. By default, all the Hyper-parameters are set with some default values. The question is, shall we change those default hyperparameters? The answer lies in the fact that how your model is behaving i.e., good or bad.
Also refer: A Comprehensive Guide to K-Nearest Neighbor (KNN) Algorithm in Python
XGBoost Hyperparameters:
For Tree-based learners the most common hyperparameters are;
max_depth: It represents the maximum depth the individual tree can grow. The complexity rises with the growth as more the depth, the more the chances that my model will get overfit.
learning_rate: The learning rate parameter defines how quickly the optimizer reaches the global minima, A higher learning rate allows it to reach the minima point very quickly but chances are that it might surpass the global minima point and the oscillations around the point occur. So it is always advisable to take a short leap, though it will take more rounds of computation to reach the minimum point but will optimize the chance of reaching it.
n_estimators: The n_estimators are the number of trees that have been connected in series for boosting purposes. The more the number, the better the performance but there is always a threat of overfitting hence, it should also be considered wisely. By default, the value is set to be 100.
colsample_bytree: This hyperparameter represents the fraction of columns to be sampled randomly by each tree in the XGBoost algorithm. The value ranges from 0 to 1, where 0 represents absolutely no column selection and 1 represents selecting all of them, by default, the value is set to 1.
Subsample: This hyperparameter represents the fraction of rows to be sampled randomly by each tree in the XGBoost algorithm. The value ranges from 0 to 1, where 0 represents absolutely no column selection and 1 represents selecting all of them, by default, the value is set to 1.
Again the question comes, what should intuitively be the reasonable value to give in the very first place? For me the approximate values should be:
max_depth: 5 – 10
n_estimators: 100(default) – 1000
learning_rate: 0.01 – 0.1
colsample_bytree: 0.5 -1
subsample : 0.6 – 1
Refer this article: Support Vector Machine Algorithm (SVM) – Understanding Kernel Trick
code
Training the model with some random parameters
xgboost = XGBRegressor(n_estimators = 500,max_depth = 10,
colsample_byTree= 0.6, learning_rate = 0.1,
subsample = 1)
xgboost.fit(X_train,y_train)
test_pred = xgboost.predict(X_test)
mean_squared_error(y_test,test_pred)
In the above picture, I tried tweaking up some values and a little improvement was shown.
One of the most profound approaches to getting the optimal hyper-parameters is to use GridSearchCV and RandomizedSearchCV, which provide us with the most optimized hyperparameters.
Use GridSearchCV to get the best combination of Hyperparameters to choose.
from sklearn.model_selection import GridSearchCV
xgboost = XGBRegressor()
params = {‘objective’:[‘reg:squarederror’],
‘max_depth’:[4,5,6,7,8,9,10],
‘n_estimators’:[100,200,300,400,500],
‘colsample_byTree’ : [0.4,0.5,0.6,0.7,0.8,0.9,1],
‘learning_rate’:[0.001,0.01,0.1,1],
‘subsample’:[0.8,0.9,1]}
gridsearchcv = GridSearchCV(xgboost,params)
gridsearchcv.fit(X_train,y_train)
gridsearchcv.best_params_
Training the model again with the obtained best parameters
xgboost = XGBRegressor(n_estimators = 200,max_depth = 4,
colsample_byTree= 0.4, learning_rate = 0.1,
subsample = 0.8)
xgboost.fit(X_train,y_train)
test_pred = xgboost.predict(X_test)
mean_squared_error(y_test,test_pred)
We saw that without any tuning, the mean_squared_error came out to 14.38, after tuning the model manually, the error came down to 12.08, and finally, when we applied GridSearchCV and got the value of Hyper-parameters, the error finally came down to 7.64.
What is Boosting

Conclusion
In this article, we saw the theoretical and practical aspects of the XGBoost algorithm, We also saw how manually tuning the hyper-parameters affects the result. We also saw the implementation of GridSearchCV and concluded the best numbers to choose from. Like XGBoost, we have more Boosting algorithms like AdaBoost and Catboost to work with as well.
Being a prominent data science institute, DataMites provides specialised training in topics including machine learning, deep learning, artificial intelligence, the internet of things. Our python Courses at DataMites have been authorised by the International Association for Business Analytics Certification (IABAC), a body with a strong reputation and high appreciation in the analytics field.
What is Ensemble Technique?
