A Guide to MLOps (Machine Learning Operations)
Discover the fundamentals of MLOps (Machine Learning Operations), including its importance, best practices, and tools for seamless model deployment. Learn how MLOps bridges the gap between machine learning development and operations to ensure scalable, efficient, and automated workflows.
 Thushara C.P
Thushara C.P

Machine Learning Operations nowadays gaining a lot of attention because of the success of Machine learning, Data Science project depends on how many users are able to consume the output of models created and trained for certain problems.
MLOps is a relatively new field and it was introduced lately in 2018 and 2019. MLOps completely works around the lifecycle of the machine learning and Data Science project, hence the name MLOps. In addition to dealing with ML model cycles, MLOps also handles operational problems like predictive maintenance, retraining approaches, and network failure.
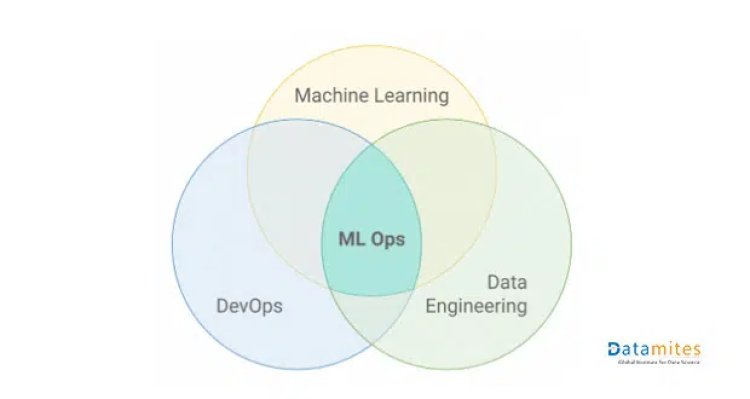
MLOps is an ML Engineering culture which aims to amalgamate;
- ML System Development (Dev)
- ML System Operations (Ops)
DevOps is an old concept and since ML is a growing field where we need to push models for users and hence the same concept of DevOps was extended to ML and coined as MLOps.
MLOps Growth:-
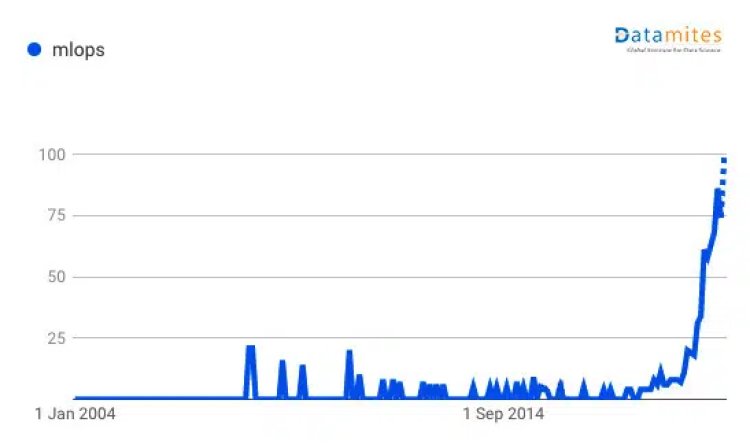
It can be clearly seen from the above graph that as the data is increasing, the need for MLOps is also increasing. This shift is caused by the ever-increasing data that has been recorded over the last decade.
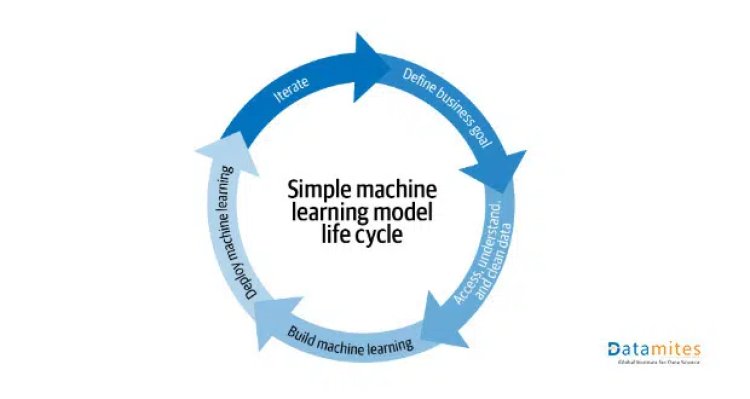
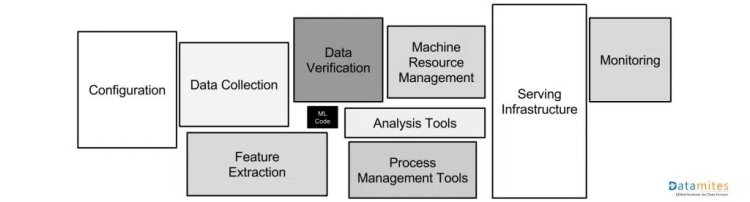
Machine Learning Model Life Cycle
This is the simplest ML model lifecycle where first we define the business goal i.e what has to solve. Once the problem statement is clear, the data is preprocessed and re-engineered for the use case. Over this feature, a machine learning model is created. Deployment on platform and model become accessible to the user and is ready for prediction.
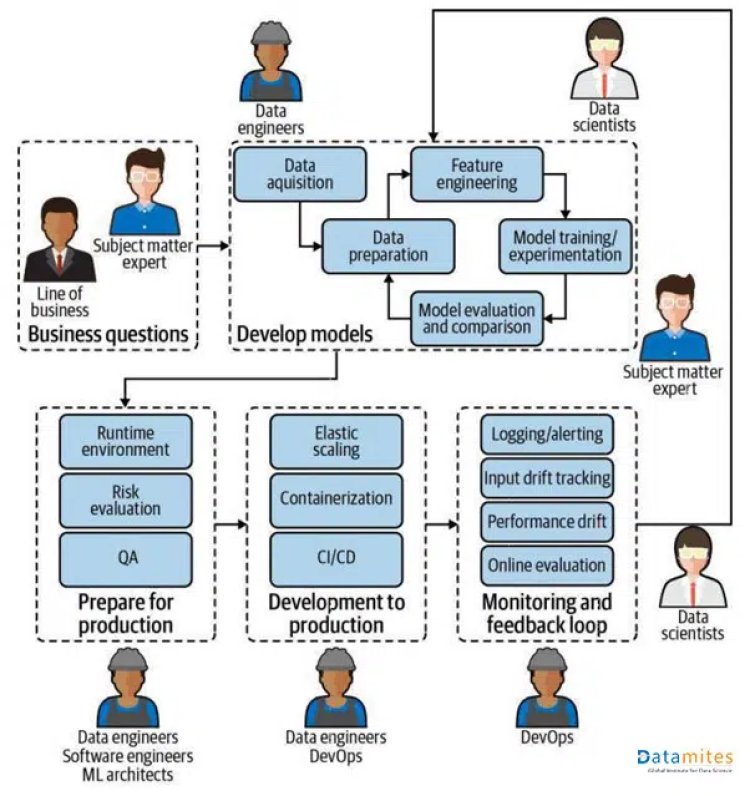
Teams Involved in MLOps Process
MLOps calls for a lot of collaboration across many teams. These teams are;
- Business Team:-They give the problem.
- Domain Expert:-These people are also from the business but they do have expertise in the domain of that specific problem they are handling now and can provide feedback on the ML system.
- Data Engineer:-This team is mostly engaged in extracting, transforming and loading the data. Storing and managing data is their top priority.
- Data Scientist:-To create models, preprocess and reengineer the data as required by the model.
- Devops:-To deploy models on various platforms.
- ML Architect:- The ML Architect works closely with DevOps team to streamline the ML model.
- Software Engineers:-To create various integration APIS with another system, front-end design.
Techniques for Implementing and Automating
- Continuous Integration
- Continuous Delivery
- Continuous Training
Continuous Integration refers to modules of Machine learning model development which include data ingestion, data preparation, feature and data engineering, model development, and model evaluation. These modules are developed by individuals like ML Engineers or Data scientists depending on the organization. If data from the source has changed or let’s assume the business team asked for the addition of a new feature in that case all module needs to be integrated correctly with the new feature.
Once a new feature is incorporated, it should be deployed continuously. If new data is ingested into the training pipeline, the training should be done continuously so that the new model can be trained and can be deployed.
ML Advise for
- Automation
- Monitoring all stages of the ML model development process like
- Integration
- Testing
- Releasing
- Deployment
- Infrastructure Management.
Comparison between traditional software development and ML system software development
| Traditional Software Development | ML Model Software Development |
| The logic is provided by the business team i.e how the problem can be solved. | Logic is taken form from data to solve the problem |
| Here you need to maintain only code, the rest of the business requirements are taken care of by the business team. | Here apart from code, model maintenance, and data maintenance everything has to be done as it has a direct impact on the solution provided. |
| The approach for traditional software development is simple as logic is coming from the business. If changes are requested by the business team, they can be directly incorporated into the system and the DevOps team with the development team do it next build. | In the case of ML software, if slightly new features or data are coming into the system, all pipelines of ML projects are to be set according to new data and retraining of the model has to be done. This is a complex process. Hence MLops team comes into the picture. |
| It follows the Waterfall and Agile model for software development techniques. | ML software needs skill sets of Data Scientists, Data Engineers and DevOps.The methodology they follow is CICDCT. |
Skill sets for MLOps
MUST-HAVE
- Sound Knowledge of any programming language like Python, Scala, or C++) to develop and improve machine learning models and pipelines (w.r.t Infrastructure as a Service).
Good amount of understanding and ability for the execution of releases, packaging, versioning and provision of the software delivery (Strong knowledge and hands-on experience with CI/CD — DevOps (e.g Jenkins, Artifactory, BigBucket, DVC, etc).
Expertise in cloud technologies/cloud computing like GCP or Azure or AWS. - Sound knowledge and understanding of ML/ Data Science concepts, processes, data and model pipelining principles, and ML algorithms.
Hands-on with tools for the integration of continuous retraining in the CI / CD process (e.g. via MLFlow with Kubeflow/Airflow).
Expertise in SQL, RDBMS, and NoSQL databases (MongoDB). - Relevant knowledge of models or risk assessment under continuous monitoring, including warning tools (Model drift, Concept drift, data drift).
- Knowledge/deployments of containerization for example Dockers, Kubernetes, or their cloud equivalents.
NICE-TO-HAVE
- Computer science master’s or doctoral degree in a relevant topic (network technologies)being familiar with data engineering tools like Apache Spark and Apache Kafka (or their cloud equivalents).
- Understanding of Infrastructure Orchestration and Automation of machine learning workflows.
- Understanding of A/B testing, Statistical hypothesis testing (based on domain).
- Understanding of Linux scripting or Command-line Interface for deployment.
- Understanding of deployment strategies like micro web frameworks and debugging for example Flask, Django, or Streamlit.
- Background in Python data-driven solution development, resulting in well-tested and reliable (preferably serverless) apps.
- Possess the DevOps mentality and be knowledgeable with agile approaches (such as Scrum).
NOT-REQUIRED
- No extensive expertise in data analysis or visualisation (BI tools).
- Knowledge of mathematics and statistics at a high level or in depth.
Challenges
- To build an integrated ML system and continue operating it on production with a huge amount of infrastructure, and teams.
- To automate the process starting from data collection, and ingestion to showing prediction to end users and while managing.
- Different teams
- Using different technologies
- Follow different routines
And also make them auditable and reproducible
3. Huge dependencies
- Data
- Model Complexity.
- Reproducibility
- Testing
- Monitoring
4. Technical Debt in machine learning system
Dependencies of other systems and on other systems can cause a lot of delays and lag. Dependency on data, and domain expertise has a huge impact on ML systems.
For further references:
Learn about the Types of Machine Learning Algorithms
BUILD A TENSORFLOW OCR IN 15 MINUTES WITH DEEP LEARNING TECHNOLOGY
Support Vector Machine Algorithm (SVM) – Understanding Kernel Trick
Different Types of Feature Scaling and Its Usage?
Outlier Detection and Its importance in Machine learning
End Notes
This blog aims to give you a starting path if you want to become an MLOps engineer. The most important thing is the skill set to become a successful MLOps engineer. There are a few more concepts which need attention and we will take that in our next blog.
DataMites is a globally recognized institute known for its comprehensive MLOps Engineer courses. Offering a range of programs in AI, deep learning, machine learning, Python, and data analytics, DataMites provides industry-relevant training. Graduates receive IABAC-accredited certification, along with access to internships and job assistance, ensuring practical experience and career growth.
Keep Learning and Keep Exploring
Also Watch – What is Machine Learning and How does it work?
