4.9 (16,400) reviews
4.9 (16,400) reviews 110,000
70,499*
NO COST EMI : 11,750 p.m for 6 Months
*Offer valid till 2nd August 2026
Instructor Led Live Online
Self Learning + Live Mentoring
In - Person Classroom Training





MODULE 1: DATA ENGINEERING INTRODUCTION
• What is Data Engineering?
• Data Engineering scope
• Data Ecosystem, Tools and platforms
• Core concepts of Data engineering
MODULE 2: DATA SOURCES AND DATA IMPORT
• Types of data sources
• Databases: SQL and Document DBs
• Managing Big data
MODULE 3: DATA INTEGRITY AND PRIVACY
• Data integrity basics
• Various aspects of data privacy
• Various data privacy frameworks and standards
• Industry related norms in data integrity and privacy: data engineering perspective
MODULE 4: DATA ENGINEERING ROLE
• Who is a data engineer?
• Various roles of data engineer
• Skills required for data engineering
• Data Engineer Collaboration with Data Scientist and other roles.
MODULE 1: PYTHON BASICS
• Introduction of python
• Installation of Python and IDE
• Python objects
• Python basic data types
• String functions part
• String functions part
• Python Operators
MODULE 2: PYTHON CONTROL STATEMENTS
• IF Conditional statement, IF-ELSE
• NESTED IF
• Python Loops Basics, WHILE Statement
• BREAK and CONTINUE statements
• FOR statements
MODULE 3: PYTHON PACKAGES
• Introduction to Packages in Python
• Datetime Package and Methods
MODULE 4: PYTHON DATA STRUCTURES
• Basic Data Structures in Python
• Basics of List
• List methods
• Tuple: Object and methods
• Sets: Object and methods
• Dictionary: Object and methods
MODULE 5: PYTHON FUNCTIONS
• Functions basics
• Function Parameter passing
• Lambda functions
• Map, reduce, filter functions
MODULE 1 : OVERVIEW OF STATISTICS
• Introduction to Statistics: Descriptive And Inferential Statistics
• a.Descriptive Statistics
• b.Inferential Statistis
• Basic Terms Of Statistics
• Types Of Data
MODULE 2 : HARNESSING DATA
• Random Sampling
• Sampling With Replacement And Without Replacement
• Cochran's Minimum Sample Size
• Types of Sampling
• Simple Random Sampling
• Stratified Random Sampling
• Cluster Random Sampling
• Systematic Random Sampling
• Multistage Sampling
• Sampling Error
• Methods Of Collecting Data
MODULE 3 : EXPLORATORY DATA ANALYSIS
• Exploratory Data Analysis Introduction
• Measures Of Central Tendencies, Measure of Spread
• Data Distribution Plot: Histogram
• Normal Distribution
• Z Value / Standard Value
• Empherical Rule and Outliers
• Central Limit Theorem
• Normality Testing
• Skewness & Kurtosis
• Measures Of Distance: Euclidean, Manhattan And Minkowski Distance
• Covariance and Correlation
MODULE 4 : HYPOTHESIS TESTING
• Hypothesis Testing Introduction
• Types of Hypothesis
• P- Value, Crtical Region
• Types of Hypothesis Testing: Parametric, Non-Parametric
• Hypothesis Testing Errors : Type I And Type II
• Two Sample Independent T-test
• Two Sample Relation T-test
• One Way Anova Test
• Application of Hypothesis Testing (Proposed)
MODULE 1: DATA WAREHOUSE FOUNDATION
• Data Warehouse Introduction
• Database vs Data Warehouse
• Data Warehouse Architecture
• Data Lake house
• ETL (Extract, Transform, and Load)
• ETL vs ELT
• Star Schema and Snowflake Schema
• Data Mart Concepts
• Data Warehouse vs Data Mart —Know the Difference
• Data Lake Introduction architecture
• Data Warehouse vs Data Lake
MODULE 2: DATA PROCESSING
• Python NumPy Package Introduction
• Array data structure, Operations
• Python Pandas package introduction
• Data structures: Series and DataFrame
• Importing data into Pandas DataFrame
• Data processing with Pandas
MODULE 3: DOCKER AND KUBERNETES FOUNDATION
• Docker Introduction
• Docker Vs.VM
• Hands-on: Running our first container
• Common commands (Running, editing,stopping,copying and managing images)YAML(Basics)
• Publishing containers to DockerHub
• Kubernetes Orchestration of Containers
• Docker swarm vs kubernetes
MODULE 4: DATA ORCHESTRATION WITH APACHE AIRFLOW
• Data Orchestration Overview
• Apache Airflow Introduction
• Airflow Architecture
• Setting up Airflow
• TAG and DAG
• Creating Airflow Workflow
• Airflow Modular Structure
• Executing Airflow
MODULE 5: DATA ENGINEERING PROJECT
• Setting Project Environment
• Data pipeline setup
• Hands-on: build scalable data pipelines
MODULE 1 : AWS DATA SERVICES INTRODUCTION
• AWS Overview and Account Setup
• AWS IAM Users, Roles and Policies
• AWS S overview
• AWS EC overview
• AWS Lamdba overview
• AWS Glue overview
• AWS Kinesis overview
• AWS Dynamodb overview
• AWS Athena overview
• AWS Redshift overview
MODULE 2 : DATA PIPELINE WITH GLUE
• AWS Glue Crawler and setup
• ETL with AWS Glue
• Data Ingesting with AWS Glue
MODULE 3 : DATA PIPELINE WITH AWS KINESIS
• AWS Kinesis overview and setup
• Data Streams with AWS Kinesis
• Data Ingesting from AWS S using AWS Kinesis
MODULE 4 : DATA WAREHOUSE WITH AWS REDSHIFT
• AWS Redshift Overview
• Analyze data using AWS Redshift from warehouses, data lakes and operations DBs
• Develop Applications using AWS Redshift cluster
• AWS Redshift federated Queries and Spectrum
MODULE 5 : DATA PIPELINE WITH AZURE SYNAPSE
• Azure Synapse setup
• Understanding Data control flow with ADF
• Data Pipelines with Azure Synapse
• Prepare and transform data with Azure Synapse Analytics
MODULE 6 : STORAGE IN AZURE
• Create Azure storage account
• Connect App to Azure Storage
• Azure Blob Storage
MODULE 7: AZURE DATA FACTORY
• Azure Data Factory Introduction
• Data transformation with Data Factory
• Data Wrangling with Data Factory
MODULE 8 : AZURE DATABRICKS
• Azure databricks introduction
• Azure databricks architecture
• Data Transformation with databricks
MODULE 9 : AZURE RDS
• Creating a Relational Database
• Querying in and out of Relational Database
• ETL from RDS to databricks
MODULE 10 : AZURE RDS
• Hands-on Project Case-study
• Setup Project Development Env
• Organization of Data Sources
• AZURE/AWS services for Data Ingestion
• Data Extraction Transformation
MODULE 1: GIT INTRODUCTION
• Purpose of Version Control
• Popular Version control tools
• Git Distribution Version Control
• Terminologies
• Git Workflow
• Git Architecture
MODULE 2: GIT REPOSITORY and GitHub
• Git Repo Introduction
• Create New Repo with Init command
• Copying existing repo
• Git user and remote node
• Git Status and rebase
• Review Repo History
• GitHub Cloud Remote Repo
MODULE 3: COMMITS, PULL, FETCH AND PUSH
• Code commits
• Pull, Fetch and conflicts resolution
• Pushing to Remote Repo
MODULE 4: TAGGING, BRANCHING AND MERGING
• Organize code with branches
• Checkout branch
• Merge branches
MODULE 5: UNDOING CHANGES
• Editing Commits
• Commit command Amend flag
• Git reset and revert
MODULE 6: GIT WITH GITHUB AND BITBUCKET
• Creating GitHub Account
• Local and Remote Repo
• Collaborating with other developers
MODULE 1 : DATABASE INTRODUCTION
MODULE 2 : SQL BASICS
MODULE 3 : DATA TYPES AND CONSTRAINTS
MODULE 4 : DATABASES AND TABLES (MySQL)
MODULE 5 : SQL JOINS
MODULE 6 : SQL COMMANDS AND CLAUSES
MODULE 7 : DOCUMENT DB/NO-SQL DB
MODULE 1: BIG DATA INTRODUCTION
• Big Data Overview
• Five Vs of Big Data
• What is Big Data and Hadoop
• Introduction to Hadoop
• Components of Hadoop Ecosystem
• Big Data Analytics Introduction
MODULE 2: HDFS AND MAP REDUCE
• HDFS – Big Data Storage
• Distributed Processing with Map Reduce
• Key Terms: Output Format
• Partitioners Combiners Shuffle and Sort
• Hands-on Map Reduce task
MODULE 3: PYSPARK FOUNDATION
• PySpark Introduction
• Resilient distributed datasets (RDD),Working with RDDs in PySpark, Spark Context , Aggregating Data with Pair RDDs
• Spark Databricks
• Spark Streaming
MODULE 1: SPARK SQL and HADOOP HIVE
• Introducing Spark SQL
• Spark SQL vs Hadoop Hive
• Working with Spark SQL Query Language
MODULE 2: KAFKA and Spark
• Kafka architecture
• Kafka workflow
• Configuring Kafka cluster
• Operations
MODULE 3: KAFKA and Spark
• Creating an HDFS cluster with containers
• Creating pyspark cluster with containers
• Processing data on hdfs cluster with pyspark cluster
MODULE 1: TABLEAU FUNDAMENTALS
• Introduction to Business Intelligence & Introduction to Tableau
• Interface Tour, Data visualization: Pie chart, Column chart, Bar chart.
• Bar chart, Tree Map, Line Chart
• Area chart, Combination Charts, Map
• Dashboards creation, Quick Filters
• Create Table Calculations
• Create Calculated Fields
• Create Custom Hierarchies
MODULE 2: POWER-BI Basics
• Power BI Introduction
• Basics Visualizations
• Dashboard Creation
• Basic Data Cleaning
• Basic DAX FUNCTION
MODULE 3: DATA TRANSFORMATION TECHNIQUES
• Exploring Query Editor
• Data Cleansing and Manipulation:
• Creating Our Initial Project File
• Connecting to Our Data Source
• Editing Rows
• Changing Data Types
• Replacing Values
MODULE 4: CONNECTING TO VARIOUS SOURCES
• Connecting to a CSV File
• Connecting to a Webpage
• Extracting Characters
• Splitting and Merging Columns
• Creating Conditional Columns
• Creating Columns from Examples
• Create Data Model










AI is the future, and DataMites helped me step into it! The online Data Science course was easy to follow, and the tutors explained everything clearly. Even after completing my course, the team supported me with placements and I successfully cracked a job! Grateful to DataMites for shaping my career.
I joined DataMites to learn Data Science and gained strong skills in ML, DL, and Statistics. Through my internship at Rubixe AI Solutions, I worked on real-world projects, which helped me land job interviews and an offer. The trainers were very supportive and explained every concept clearly. Thanks to DataMites, my data science journey was smooth and successful.
My mentor, a DataMites alumnus, suggested I join the Data Science course, and it was one of my best decisions! The offline classes were interactive and full of guidance, and I got the chance to intern at Rubixe AI Solutions. The placement team was very supportive and helped me perfect my resume. Truly thankful to DataMites for this amazing learning journey.
I joined DataMites after completing my engineering in Computer Science and became a Certified Data Scientist. With their support, I completed an internship at Rubix AI Solutions and now work as an AI intern at Inventor Hub. DataMites made learning statistics and data science easy with clear guidance and great materials. I’m truly thankful for their support.
I joined DataMites for the Certified Data Scientist online course, and it was a great experience! The real-time projects helped me apply my learning practically, and the placement support added real value to my career restart after 8 years. DataMites is the perfect platform to learn, grow, and begin your data science journey.
I joined DataMites for the Data Science course and learned Python, SQL, Machine Learning, and Deep Learning through hands-on projects. The trainers are excellent at explaining concepts clearly. The placement team is very supportive and provides great opportunities thanks to DataMites for helping me start my data science journey.
I joined DataMites after my B.Tech when I developed an interest in Data Science and Machine Learning. The training was well-structured, and I even got an internship opportunity that helped me gain real experience. The placement team was super supportive and guided me through every step. Thanks to DataMites, I’m now placed at Horizon Broadband Pvt. Ltd.
I joined DataMites after completing my BCA, and it was the best decision for my data science career! I learned Python, SQL, Machine Learning, Deep Learning, and NLP, and worked on several capstone and client projects that gave me real-world experience. The trainers and team were always friendly and supportive, patiently clearing all my doubts. Thanks to DataMites, I’m confident and job-ready in data science
I started my data science journey with DataMites, and it’s been an amazing experience! The Certified Data Scientist Program helped me learn everything from scratch through hands-on projects and an internship. The placement team was incredibly supportive, always ready to clarify my doubts. Thanks to their guidance, I successfully got placed. Highly recommend DataMites to anyone starting their data science career
Enrolling at DataMites was one of the best decisions I made for my career. Coming from a freelance writing background with no prior technical experience, I was initially unsure about stepping into the field of data analytics. But DataMites made the transition smooth and achievable. I’d highly recommend them to anyone looking for a guided, industry-ready data analytics course. A true DataMites success story!
Data engineering refers to the process of designing, constructing, and managing the infrastructure and systems necessary for the collection, storage, processing, and analysis of large volumes of data, ensuring its availability, reliability, and accessibility for data-driven decision-making.
a. Acquire a solid foundation in mathematics, statistics, and programming.
b. Gain proficiency in data manipulation, database management, and data integration.
c. Develop expertise in big data technologies, such as Hadoop, Spark, and cloud platforms.
d. Build a portfolio of data engineering projects showcasing your skills and capabilities.
e. Seek internships or entry-level positions in organizations that require data engineering expertise.
f. Continuously update your knowledge by staying informed about emerging technologies and industry trends.
The timeframe for becoming a data engineer can vary depending on individual circumstances and the learning path chosen. Generally, it may take anywhere from six months to two years to gain the necessary skills and experience to start a career as a data engineer.
a. Gain in-depth knowledge of data engineering concepts, tools, and techniques.
b. Acquire hands-on experience with industry-standard data engineering technologies.
c. Enhance job prospects and increase earning potential in the rapidly growing field of data engineering.
d. Develop a strong foundation for career progression and opportunities in data-related roles.
Prerequisites for enrolling in a data engineering course in Itanagar:
a. Basic understanding of mathematics, statistics, and programming concepts.
b. Familiarity with databases and SQL.
c. Proficiency in at least one programming language, such as Python or Java.
d. Knowledge of data manipulation and data analysis techniques.
e. Some courses or programs may have specific prerequisites or recommended prior experience, so it is essential to review the requirements of the chosen course or institute.
The cost of data engineering training can vary depending on the institute, program duration, and the level of instruction. In general, the data engineer training fees in Itanagar can be anywhere from 40,000 INR to INR 1,00,000. It is advisable to research different training providers in Itanagar to determine the specific costs associated with their courses.
Datamites is considered one of the best institutes for data engineering training. With comprehensive curriculum, industry-relevant projects, and experienced instructors, the institute provides a strong foundation in data engineering concepts, tools, and techniques. Its focus on practical hands-on learning and industry connections makes them a preferred choice for individuals aspiring to excel in the field of data engineering.
After completing data engineering training, individuals can explore various job opportunities such as Data Engineer, Data Analyst, Big Data Engineer, ETL Developer, Database Administrator, or Cloud Data Engineer. These roles can be found in diverse industries including technology, finance, healthcare, e-commerce, and more.
Essential skills for a data engineer:
a. Proficiency in programming languages like Python, Java, or Scala.
b. Strong knowledge of SQL and experience with database management systems.
c. Understanding of big data technologies like Hadoop, Spark, and NoSQL databases.
d. Data modeling and data architecture design skills.
e. Familiarity with cloud platforms such as AWS, Azure, or Google Cloud.
f. Experience in data pipeline development, data integration, and ETL processes.
g. Problem-solving and analytical thinking abilities.
h. Effective communication and collaboration skills.
The average salary for Data Engineers in Itanagar can vary depending on factors such as experience, skills, industry, and organization. However, the average salary for Data Engineer is ₹8,90,000 per year in the India, as reported by Glassdoor.
Data Analytics offers promising career prospects, with a wide range of job opportunities available. Professionals in this field can find employment in various sectors, including technology companies, consulting firms, financial institutions, healthcare organizations, e-commerce companies, and government agencies. Data Analytics Job titles may include Data Analyst, Data Scientist, Business Intelligence Analyst, Data Engineer, Machine Learning Engineer, and Data Consultant, among others.
While a specific educational path may not be mandatory for a career in data analytics, having a degree in a related field can be advantageous. Employers often prefer candidates with a bachelor's or master's degree in mathematics, statistics, computer science, economics, business analytics, or a related discipline. Additionally, certifications and specialized training in data analytics, data science, or relevant tools can further enhance your skills and marketability.
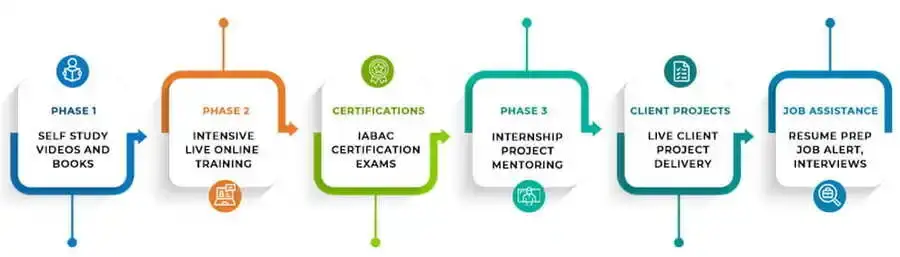
To obtain data engineering training in Itanagar, you can enroll in courses offered by reputable training institutes such as DataMites®, either through their online programs or by attending in-person classes if available.
The DataMites Certified Data Engineer Courses in Itanagar covers a comprehensive curriculum that includes topics like data integration, data modeling, ETL processes, data warehousing, big data technologies, and cloud platforms. Hands-on projects and real-world case studies are also included to enhance practical skills.
The Data Engineer Course at DataMites® in Itanagar is open to individuals who have a basic understanding of mathematics, statistics, and programming. Aspiring data engineers, IT professionals, software engineers, and data enthusiasts looking to transition into data engineering roles are eligible to enroll.
The duration of the DataMites Data Engineer Course in Itanagar can vary based on the learning mode chosen. Typically, it ranges is 6-Month and 150+ Learning Hours for online instructor-led training and may vary for self-paced learning options.
Pursuing online data engineer training from DataMites® offers several benefits, including flexibility in learning at your own pace and convenience, access to industry-expert instructors, hands-on assignments and projects, interactive learning materials, and networking opportunities with a global community of learners.
The cost of the DataMites Data Engineer Training in Itanagar may vary based on factors such as the learning mode chosen and any additional services or resources included. However, the data engineer course fee in Itanagar can vary from INR 26,548 to INR 68,000.
Yes, DataMites® provides classroom training for Data Engineer courses in Itanagar, allowing students to have in-person learning experiences and interactions with instructors and peers. We do provide data engineer offline training in Itanagar ON DEMAND.
The instructor for the Data Engineer Course in Itanagar at DataMites® is a qualified and experienced professional with expertise in data engineering and related fields. DataMites® ensures that their instructors have industry experience and possess in-depth knowledge of the subject matter.
Flexi-Pass is a concept offered by DataMites® that provides learners with the flexibility to access recorded sessions of their courses. It allows individuals to revisit or catch up on missed classes, providing convenience and ensuring that learners have comprehensive access to course content.
Yes, upon successful completion of the Data Engineer training from DataMites®, you will receive certifications. DataMites® offers industry-recognized certifications that validate your skills and knowledge in data engineering, enhancing your credibility and increasing your job prospects in the field.
The DataMites Placement Assistance Team(PAT) facilitates the aspirants in taking all the necessary steps in starting their career in Data Science. Some of the services provided by PAT are: -
The DataMites Placement Assistance Team(PAT) conducts sessions on career mentoring for the aspirants with a view of helping them realize the purpose they have to serve when they step into the corporate world. The students are guided by industry experts about the various possibilities in the Data Science career, this will help the aspirants to draw a clear picture of the career options available. Also, they will be made knowledgeable about the various obstacles they are likely to face as a fresher in the field, and how they can tackle.
No, PAT does not promise a job, but it helps the aspirants to build the required potential needed in landing a career. The aspirants can capitalize on the acquired skills, in the long run, to a successful career in Data Science.