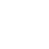4.9 (24,000) reviews
4.9 (24,000) reviews EUR 1,860
EUR 1,159*
*Offer valid till 29th March 2026
Instructor Led Live Online
Self Learning + Live Mentoring
Customize Your Training


MODULE 1: DATA SCIENCE ESSENTIALS
• Introduction to Data Science
• Evolution of Data Science
• Big Data Vs Data Science
• Data Science Terminologies
• Data Science vs AI/Machine Learning
• Data Science vs Analytics
MODULE 2: DATA SCIENCE DEMO
• Business Requirement: Use Case
• Data Preparation
• Machine learning Model building
• Prediction with ML model
• Delivering Business Value.
MODULE 3: ANALYTICS CLASSIFICATION
• Types of Analytics
• Descriptive Analytics
• Diagnostic Analytics
• Predictive Analytics
• Prescriptive Analytics
• EDA and insight gathering demo in Tableau
MODULE 4: DATA SCIENCE AND RELATED FIELDS
• Introduction to AI
• Introduction to Computer Vision
• Introduction to Natural Language Processing
• Introduction to Reinforcement Learning
• Introduction to GAN
• Introduction to Generative Passive Models
MODULE 5: DATA SCIENCE ROLES & WORKFLOW
• Data Science Project workflow
• Roles: Data Engineer, Data Scientist, ML Engineer and MLOps Engineer
• Data Science Project stages.
MODULE 6: MACHINE LEARNING INTRODUCTION
• What Is ML? ML Vs AI
• ML Workflow, Popular ML Algorithms
• Clustering, Classification And Regression
• Supervised Vs Unsupervised
MODULE 7: DATA SCIENCE INDUSTRY APPLICATIONS
• Data Science in Finance and Banking
• Data Science in Retail
• Data Science in Health Care
• Data Science in Logistics and Supply Chain
• Data Science in Technology Industry
• Data Science in Manufacturing
• Data Science in Agriculture
MODULE 1: PYTHON BASICS
• Introduction of python
• Installation of Python and IDE
• Python Variables
• Python basic data types
• Number & Booleans, strings
• Arithmetic Operators
• Comparison Operators
• Assignment Operators
MODULE 2: PYTHON CONTROL STATEMENTS
• IF Conditional statement
• IF-ELSE
• NESTED IF
• Python Loops basics
• WHILE Statement
• FOR statements
• BREAK and CONTINUE statements
MODULE 3: PYTHON DATA STRUCTURES
• Basic data structure in python
• Basics of List
• List: Object, methods
• Tuple: Object, methods
• Sets: Object, methods
• Dictionary: Object, methods
MODULE 4: PYTHON FUNCTIONS
• Functions basics
• Function Parameter passing
• Lambda functions
• Map, reduce, filter functions
MODULE 1: OVERVIEW OF STATISTICS
• Introduction to Statistics
• Descriptive And Inferential Statistics
• Basic Terms Of Statistics
• Types Of Data
MODULE 2: HARNESSING DATA
• Random Sampling
• Sampling With Replacement And Without Replacement
• Cochran's Minimum Sample Size
• Types of Sampling
• Simple Random Sampling
• Stratified Random Sampling
• Cluster Random Sampling
• Systematic Random Sampling
• Multi stage Sampling
• Sampling Error
• Methods Of Collecting Data
MODULE 3: EXPLORATORY DATA ANALYSIS
• Exploratory Data Analysis Introduction
• Measures Of Central Tendencies: Mean,Median And Mode
• Measures Of Central Tendencies: Range, Variance And Standard Deviation
• Data Distribution Plot: Histogram
• Normal Distribution & Properties
• Z Value / Standard Value
• Empirical Rule and Outliers
• Central Limit Theorem
• Normality Testing
• Skewness & Kurtosis
• Measures Of Distance: Euclidean, Manhattan And Minkowski Distance
• Covariance & Correlation
MODULE 4: HYPOTHESIS TESTING
• Hypothesis Testing Introduction
• P- Value, Critical Region
• Types of Hypothesis Testing
• Hypothesis Testing Errors : Type I And Type II
• Two Sample Independent T-test
• Two Sample Relation T-test
• One Way Anova Test
• Application of Hypothesis testing
MODULE 1: MACHINE LEARNING INTRODUCTION
• What Is ML? ML Vs AI
• Clustering, Classification And Regression
• Supervised Vs Unsupervised
MODULE 2: PYTHON NUMPY PACKAGE
• Introduction to Numpy Package
• Array as Data Structure
• Core Numpy functions
• Matrix Operations, Broadcasting in Arrays
MODULE 3: PYTHON PANDAS PACKAGE
• Introduction to Pandas package
• Series in Pandas
• Data Frame in Pandas
• File Reading in Pandas
• Data munging with Pandas
MODULE 4: VISUALIZATION WITH PYTHON - Matplotlib
• Visualization Packages (Matplotlib)
• Components Of A Plot, Sub-Plots
• Basic Plots: Line, Bar, Pie, Scatter
MODULE 5: PYTHON VISUALIZATION PACKAGE - SEABORN
• Seaborn: Basic Plot
• Advanced Python Data Visualizations
MODULE 6: ML ALGO: LINEAR REGRESSSION
• Introduction to Linear Regression
• How it works: Regression and Best Fit Line
• Modeling and Evaluation in Python
MODULE 7: ML ALGO: LOGISTIC REGRESSION
• Introduction to Logistic Regression
• How it works: Classification & Sigmoid Curve
• Modeling and Evaluation in Python
MODULE 8: ML ALGO: K MEANS CLUSTERING
• Understanding Clustering (Unsupervised)
• K Means Algorithm
• How it works : K Means theory
• Modeling in Python
MODULE 9: ML ALGO: KNN
• Introduction to KNN
• How It Works: Nearest Neighbor Concept
• Modeling and Evaluation in Python
MODULE 1: FEATURE ENGINEERING
• Introduction to Feature Engineering
• Feature Engineering Techniques: Encoding, Scaling, Data Transformation
• Handling Missing values, handling outliers
• Creation of Pipeline
• Use case for feature engineering
MODULE 2: ML ALGO: SUPPORT VECTOR MACHINE (SVM)
• Introduction to SVM
• How It Works: SVM Concept, Kernel Trick
• Modeling and Evaluation of SVM in Python
MODULE 3: PRINCIPAL COMPONENT ANALYSIS (PCA)
• Building Blocks Of PCA
• How it works: Finding Principal Components
• Modeling PCA in Python
MODULE 4: ML ALGO: DECISION TREE
• Introduction to Decision Tree & Random Forest
• How it works
• Modeling and Evaluation in Python
MODULE 5: ENSEMBLE TECHNIQUES - BAGGING
• Introduction to Ensemble technique
• Bagging and How it works
• Modeling and Evaluation in Python
MODULE 6: ML ALGO: NAÏVE BAYES
• Introduction to Naive Bayes
• How it works: Bayes' Theorem
• Naive Bayes For Text Classification
• Modeling and Evaluation in Python
MODULE 7: GRADIENT BOOSTING, XGBOOST
• Introduction to Boosting and XGBoost
• How it works?
• Modeling and Evaluation of in Python
MODULE 1: TIME SERIES FORECASTING - ARIMA
• What is Time Series?
• Trend, Seasonality, cyclical and random
• Stationarity of Time Series
• Autoregressive Model (AR)
• Moving Average Model (MA)
• ARIMA Model
• Autocorrelation and AIC
• Time Series Analysis in Python
MODULE 2: SENTIMENT ANALYSIS
• Introduction to Sentiment Analysis
• NLTK Package
• Case study: Sentiment Analysis on Movie Reviews
MODULE 3: REGULAR EXPRESSIONS WITH PYTHON
• Regex Introduction
• Regex codes
• Text extraction with Python Regex
MODULE 4: ML MODEL DEPLOYMENT WITH FLASK
• Introduction to Flask
• URL and App routing
• Flask application – ML Model deployment
MODULE 5: ADVANCED DATA ANALYSIS WITH MS EXCEL
• MS Excel core Functions
• Advanced Functions (VLOOKUP, INDIRECT..)
• Linear Regression with EXCEL
• Data Table
• Goal Seek Analysis
• Pivot Table
• Solving Data Equation with EXCEL
MODULE 6: AWS CLOUD FOR DATA SCIENCE
• Introduction of cloud
• Difference between GCC, Azure, AWS
• AWS Service ( EC2 instance)
MODULE 7: AZURE FOR DATA SCIENCE
• Introduction to AZURE ML studio
• Data Pipeline
• ML modeling with Azure
MODULE 8: INTRODUCTION TO DEEP LEARNING
• Introduction to Artificial Neural Network, Architecture
• Artificial Neural Network in Python
• Introduction to Convolutional Neural Network, Architecture
• Convolutional Neural Network in Python
MODULE 1: DATABASE INTRODUCTION
• DATABASE Overview
• Key concepts of database management
• Relational Database Management System
• CRUD operations
MODULE 2: SQL BASICS
• Introduction to Databases
• Introduction to SQL
• SQL Commands
• MY SQL workbench installation
MODULE 3: DATA TYPES AND CONSTRAINTS
• Numeric, Character, date time data type
• Primary key, Foreign key, Not null
• Unique, Check, default, Auto increment
MODULE 4: DATABASES AND TABLES (MySQL)
• Create database
• Delete database
• Show and use databases
• Create table, Rename table
• Delete table, Delete table records
• Create new table from existing data types
• Insert into, Update records
• Alter table
MODULE 5: SQL JOINS
• Inner Join, Outer Join
• Left Join, Right Join
• Self Join, Cross join
• Windows function: Over, Partition, Rank
MODULE 6: SQL COMMANDS AND CLAUSES
• Select, Select distinct
• Aliases, Where clause
• Relational operators, Logical
• Between, Order by, In
• Like, Limit, null/not null, group by
• Having, Sub queries
MODULE 7 : DOCUMENT DB/NO-SQL DB
• Introduction of Document DB
• Document DB vs SQL DB
• Popular Document DBs
• MongoDB basics
• Data format and Key methods
MODULE 1: GIT INTRODUCTION
• Purpose of Version Control
• Popular Version control tools
• Git Distribution Version Control
• Terminologies
• Git Workflow
• Git Architecture
MODULE 2: GIT REPOSITORY and GitHub
• Git Repo Introduction
• Create New Repo with Init command
• Git Essentials: Copy & User Setup
• Mastering Git and GitHub
MODULE 3: COMMITS, PULL, FETCH AND PUSH
• Code Commits
• Pull, Fetch and Conflicts resolution
• Pushing to Remote Repo
MODULE 4: TAGGING, BRANCHING AND MERGING
• Organize code with branches
• Checkout branch
• Merge branches
• Editing Commits
• Commit command Amend flag
• Git reset and revert
MODULE 5: GIT WITH GITHUB AND BITBUCKET
• Creating GitHub Account
• Local and Remote Repo
• Collaborating with other developers
MODULE 1: BIG DATA INTRODUCTION
• Big Data Overview
• Five Vs of Big Data
• What is Big Data and Hadoop
• Introduction to Hadoop
• Components of Hadoop Ecosystem
• Big Data Analytics Introduction
MODULE 2 : HDFS AND MAP REDUCE
• HDFS – Big Data Storage
• Distributed Processing with Map Reduce
• Mapping and reducing stages concepts
• Key Terms: Output Format, Partitioners,
• Combiners, Shuffle, and Sort
MODULE 3: PYSPARK FOUNDATION
• PySpark Introduction
• Spark Configuration
• Resilient distributed datasets (RDD)
• Working with RDDs in PySpark
• Aggregating Data with Pair RDDs
MODULE 4: SPARK SQL and HADOOP HIVE
• Introducing Spark SQL
• Spark SQL vs Hadoop Hive
MODULE 1: TABLEAU FUNDAMENTALS
• Introduction to Business Intelligence & Introduction to Tableau
• Interface Tour, Data visualization: Pie chart, Column chart, Bar chart.
• Bar chart, Tree Map, Line Chart
• Area chart, Combination Charts, Map
• Dashboards creation, Quick Filters
• Create Table Calculations
• Create Calculated Fields
• Create Custom Hierarchies
MODULE 2: POWER-BI BASICS
• Power BI Introduction
• Basics Visualizations
• Dashboard Creation
• Basic Data Cleaning
• Basic DAX FUNCTION
MODULE 3 : DATA TRANSFORMATION TECHNIQUES
• Exploring Query Editor
• Data Cleansing and Manipulation:
• Creating Our Initial Project File
• Connecting to Our Data Source
• Editing Rows
• Changing Data Types
• Replacing Values
MODULE 4: CONNECTING TO VARIOUS DATA SOURCES
• Connecting to a CSV File
• Connecting to a Webpage
• Extracting Characters
• Splitting and Merging Columns
• Creating Conditional Columns
• Creating Columns from Examples
• Create Data Model
I joined DataMites for the Certified Data Scientist online course, and it was a great experience! The real-time projects helped me apply my learning practically, and the placement support added real value to my career restart after 8 years. DataMites is the perfect platform to learn, grow, and begin your data science journey.
I joined DataMites for the Data Science course and learned Python, SQL, Machine Learning, and Deep Learning through hands-on projects. The trainers are excellent at explaining concepts clearly. The placement team is very supportive and provides great opportunities thanks to DataMites for helping me start my data science journey.
I joined DataMites after my B.Tech when I developed an interest in Data Science and Machine Learning. The training was well-structured, and I even got an internship opportunity that helped me gain real experience. The placement team was super supportive and guided me through every step. Thanks to DataMites, I’m now placed at Horizon Broadband Pvt. Ltd.
I joined DataMites after completing my BCA, and it was the best decision for my data science career! I learned Python, SQL, Machine Learning, Deep Learning, and NLP, and worked on several capstone and client projects that gave me real-world experience. The trainers and team were always friendly and supportive, patiently clearing all my doubts. Thanks to DataMites, I’m confident and job-ready in data science
I started my data science journey with DataMites, and it’s been an amazing experience! The Certified Data Scientist Program helped me learn everything from scratch through hands-on projects and an internship. The placement team was incredibly supportive, always ready to clarify my doubts. Thanks to their guidance, I successfully got placed. Highly recommend DataMites to anyone starting their data science career
Enrolling at DataMites was one of the best decisions I made for my career. Coming from a freelance writing background with no prior technical experience, I was initially unsure about stepping into the field of data analytics. But DataMites made the transition smooth and achievable. I’d highly recommend them to anyone looking for a guided, industry-ready data analytics course. A true DataMites success story!
Data Science is the dedicated discipline focused on extracting valuable insights and knowledge from extensive sets of both structured and unstructured data. It employs an array of techniques, algorithms, and systems to analyze, interpret, and present data in a meaningful manner.
The operational process of Data Science entails the systematic collection, cleaning, and analysis of data to unveil significant patterns and trends. Utilizing statistical models, machine learning algorithms, and data visualization techniques, informed decisions are made based on the discovered insights.
Data Science finds practical applications in predictive analytics, fraud detection, recommendation systems, sentiment analysis, and the optimization of business processes across diverse industries, showcasing its versatility and significance.
Critical components of a Data Science pipeline encompass data collection, data cleaning, exploratory data analysis (EDA), feature engineering, model training, model evaluation, and deployment. These stages collectively contribute to the holistic process of extracting insights from data.
Python and R emerge as frequently employed programming languages in Data Science. Their popularity stems from the availability of extensive libraries and frameworks facilitating tasks such as data manipulation, analysis, and the implementation of machine learning algorithms.
Machine learning plays a pivotal role in Data Science by empowering systems to autonomously discern patterns from data, enabling predictions and decisions without explicit programming. This capability enhances the extraction of valuable insights from complex datasets.
The relationship between Big Data and Data Science is intimate, with Data Science being instrumental in handling and analyzing extensive datasets that conventional data processing tools may struggle to manage. The application of Data Science methodologies and algorithms becomes crucial for extracting meaningful information from the vast expanse of Big Data.
Data Science finds practical application in diverse sectors such as healthcare, finance, marketing, and manufacturing. Its role extends to optimizing operations, refining decision-making processes, and enhancing overall business performance within these industries.
While Data Science encompasses a broader spectrum of activities, including data cleaning, exploration, and visualization, machine learning specifically focuses on crafting algorithms that empower systems to autonomously learn patterns and make predictions.
Eligible candidates for Data Science certification courses come from diverse backgrounds, including IT professionals, statisticians, analysts, and business experts. A foundational understanding of statistics and programming proves beneficial for individuals venturing into the realm of Data Science.
As of 2024, Vienna's data science job market is experiencing robust growth, with a noticeable increase in demand for skilled professionals.
The Certified Data Scientist Course in Vienna is a premier option for individuals seeking comprehensive data science training, covering essential areas such as machine learning and data analysis.
In Vienna, data science internships play a crucial role, offering practical experience that significantly enhances one's employability within the expanding field.
Certainly, entry-level individuals can pursue data science courses and successfully secure employment in Vienna, as companies actively seek skilled newcomers.
No, having a postgraduate degree is not a mandatory prerequisite for joining data science training courses in Vienna. Many programs welcome candidates with relevant undergraduate backgrounds.
Vienna businesses leverage data science to foster growth by refining decision-making processes, streamlining operations, and enhancing overall customer experiences.
In Vienna's financial sector, data science finds practical applications in areas such as risk management, fraud detection, and predictive analytics, significantly enhancing industry efficiency.
In Vienna, data science plays a pivotal role in e-commerce by driving recommendation systems, personalized marketing, and accurate demand forecasting, elevating the overall customer experience.
Within Vienna's cybersecurity landscape, data science is crucial for detecting anomalies, identifying patterns, and fortifying threat detection and prevention measures.
In Vienna's manufacturing and supply chain management domains, data science optimizes production processes, predicts demand, and enhances logistics efficiency for improved operational performance.
The salary of a data scientist in Vienna ranges from EUR 60,000 per year according to a Glassdoor report.
The Datamites™ Certified Data Scientist course covers crucial aspects of data science, including programming, statistics, machine learning, and business knowledge. With a primary emphasis on Python as the main programming language, it accommodates professionals familiar with R. The comprehensive curriculum establishes a strong foundation, and successful completion, coupled with the IABAC™ certificate, positions individuals as skilled data science professionals prepared for industry challenges.
While advantageous, a background in statistics is not always obligatory for starting a data science career in Vienna. The emphasis is often on proficiency in relevant tools, programming languages, and practical problem-solving skills.
DataMites provides a diverse range of data science certifications in Vienna, including a Diploma in Data Science, Certified Data Scientist, Data Science for Managers, Data Science Associate, Statistics for Data Science, Python for Data Science, and specialized certifications in areas like Marketing, Operations, Finance, and HR.
For those new to the field in Vienna, introductory courses such as Certified Data Scientist, Data Science Foundation, and Diploma in Data Science offer foundational training in data science.
DataMites in Vienna caters to working professionals aiming to enhance their expertise with various courses, including Statistics for Data Science, Data Science with R Programming, Python for Data Science, Data Science Associate, and specialized certifications in Operations, Marketing, HR, and Finance.
The data science course in Vienna extends over 8 months.
Career mentoring sessions at DataMites are personalized and interactive, providing customized guidance on resume development, interview preparation, and effective career strategies. These sessions aim to equip participants with valuable insights to enhance their professional journey within the field of data science.
Upon completing the training, participants are awarded the prestigious IABAC Certification from DataMites. This internationally recognized certification serves as proof of proficiency in data science principles and practical applications.
To excel in data science, a strong foundation in mathematics, statistics, and programming is crucial. Developing robust analytical skills, proficiency in languages such as Python or R, and hands-on experience with tools like Hadoop or SQL databases is recommended.
Selecting online data science training in Vienna offers benefits such as flexibility, accessibility, a comprehensive curriculum aligned with industry needs, industry-relevant content, experienced instructors, interactive learning experiences, and the freedom to learn at one's own pace.
DataMites data science training fee in Vienna ranges from EUR 488 to EUR 1,220, depending on the chosen program.
DataMites presents a Data Scientist Course in Vienna that integrates practical learning through over 10 capstone projects and a dedicated client/live project. This hands-on approach ensures participants acquire real-world experience and apply their skills in practical scenarios.
Trainers at DataMites are selected based on their certifications, extensive industry experience, and expertise in the subject matter. This meticulous selection process ensures participants receive top-quality instruction from seasoned professionals.
DataMites offers flexible learning methods, including Live Online sessions and self-study options, accommodating the diverse preferences of participants.
The FLEXI-PASS feature in DataMites' Certified Data Scientist Course allows participants to engage in multiple batches, offering the flexibility to revisit topics, address queries, and reinforce understanding across various sessions for a comprehensive grasp of the course content.
Certainly, upon successfully concluding the DataMites' Data Science Course, participants have the option to acquire a Certificate of Completion through the online portal. This certification serves as a validation of their proficiency in data science, strengthening their position in the competitive job market.
Indeed, participants are required to bring valid Photo ID Proof, such as a National ID card or Driving License, to obtain a Participation Certificate and facilitate the scheduling of the certification exam as necessary.
In case of a missed session during the DataMites Certified Data Scientist Course in Vienna, participants typically have the option to access recorded sessions or attend support sessions to make up for any missed content and address queries.
Potential participants at DataMites are encouraged to attend a demo class before making any payments for the Certified Data Scientist Course in Vienna. This allows them to evaluate the teaching style, course content, and overall structure before committing.
Certainly, DataMites integrates internships into its certified data scientist course in Vienna, providing a unique learning experience that combines theoretical knowledge with practical industry exposure. This approach enhances skills and opens up job opportunities in the dynamic field of data science.
Upon successful completion of the Data Science training, you will be granted an internationally recognized IABAC® certification. This certification affirms your expertise in the field, elevating your employability on a global scale.
The DataMites Placement Assistance Team(PAT) facilitates the aspirants in taking all the necessary steps in starting their career in Data Science. Some of the services provided by PAT are: -
The DataMites Placement Assistance Team(PAT) conducts sessions on career mentoring for the aspirants with a view of helping them realize the purpose they have to serve when they step into the corporate world. The students are guided by industry experts about the various possibilities in the Data Science career, this will help the aspirants to draw a clear picture of the career options available. Also, they will be made knowledgeable about the various obstacles they are likely to face as a fresher in the field, and how they can tackle.
No, PAT does not promise a job, but it helps the aspirants to build the required potential needed in landing a career. The aspirants can capitalize on the acquired skills, in the long run, to a successful career in Data Science.