4.9 (20,900) reviews
4.9 (20,900) reviews 110,000
68,822*
NO COST EMI : 11,470 p.m for 6 Months
*Offer valid till 19th July 2026
Instructor Led Live Online
Self Learning + Live Mentoring
In - Person Classroom Training





MODULE 1: DATA SCIENCE ESSENTIALS
• Introduction to Data Science
• Evolution of Data Science
• Big Data Vs Data Science
• Data Science Terminologies
• Data Science vs AI/Machine Learning
• Data Science vs Analytics
MODULE 2: DATA SCIENCE DEMO
• Business Requirement: Use Case
• Data Preparation
• Machine learning Model building
• Prediction with ML model
• Delivering Business Value.
MODULE 3: ANALYTICS CLASSIFICATION
• Types of Analytics
• Descriptive Analytics
• Diagnostic Analytics
• Predictive Analytics
• Prescriptive Analytics
• EDA and insight gathering demo in Tableau
MODULE 4: DATA SCIENCE AND RELATED FIELDS
• Introduction to AI
• Introduction to Computer Vision
• Introduction to Natural Language Processing
• Introduction to Reinforcement Learning
• Introduction to GAN
• Introduction to Generative Passive Models
MODULE 5: DATA SCIENCE ROLES & WORKFLOW
• Data Science Project workflow
• Roles: Data Engineer, Data Scientist, ML Engineer and MLOps Engineer
• Data Science Project stages.
MODULE 6: MACHINE LEARNING INTRODUCTION
• What Is ML? ML Vs AI
• ML Workflow, Popular ML Algorithms
• Clustering, Classification And Regression
• Supervised Vs Unsupervised
MODULE 7: DATA SCIENCE INDUSTRY APPLICATIONS
• Data Science in Finance and Banking
• Data Science in Retail
• Data Science in Health Care
• Data Science in Logistics and Supply Chain
• Data Science in Technology Industry
• Data Science in Manufacturing
• Data Science in Agriculture
MODULE 1: PYTHON BASICS
• Introduction of python
• Installation of Python and IDE
• Python Variables
• Python basic data types
• Number & Booleans, strings
• Arithmetic Operators
• Comparison Operators
• Assignment Operators
MODULE 2: PYTHON CONTROL STATEMENTS
• IF Conditional statement
• IF-ELSE
• NESTED IF
• Python Loops basics
• WHILE Statement
• FOR statements
• BREAK and CONTINUE statements
MODULE 3: PYTHON DATA STRUCTURES
• Basic data structure in python
• Basics of List
• List: Object, methods
• Tuple: Object, methods
• Sets: Object, methods
• Dictionary: Object, methods
MODULE 4: PYTHON FUNCTIONS
• Functions basics
• Function Parameter passing
• Lambda functions
• Map, reduce, filter functions
MODULE 1: OVERVIEW OF STATISTICS
• Introduction to Statistics
• Descriptive And Inferential Statistics
• Basic Terms Of Statistics
• Types Of Data
MODULE 2: HARNESSING DATA
• Random Sampling
• Sampling With Replacement And Without Replacement
• Cochran's Minimum Sample Size
• Types of Sampling
• Simple Random Sampling
• Stratified Random Sampling
• Cluster Random Sampling
• Systematic Random Sampling
• Multi stage Sampling
• Sampling Error
• Methods Of Collecting Data
MODULE 3: EXPLORATORY DATA ANALYSIS
• Exploratory Data Analysis Introduction
• Measures Of Central Tendencies: Mean,Median And Mode
• Measures Of Central Tendencies: Range, Variance And Standard Deviation
• Data Distribution Plot: Histogram
• Normal Distribution & Properties
• Z Value / Standard Value
• Empirical Rule and Outliers
• Central Limit Theorem
• Normality Testing
• Skewness & Kurtosis
• Measures Of Distance: Euclidean, Manhattan And Minkowski Distance
• Covariance & Correlation
MODULE 4: HYPOTHESIS TESTING
• Hypothesis Testing Introduction
• P- Value, Critical Region
• Types of Hypothesis Testing
• Hypothesis Testing Errors : Type I And Type II
• Two Sample Independent T-test
• Two Sample Relation T-test
• One Way Anova Test
• Application of Hypothesis testing
MODULE 1: MACHINE LEARNING INTRODUCTION
• What Is ML? ML Vs AI
• Clustering, Classification And Regression
• Supervised Vs Unsupervised
MODULE 2: PYTHON NUMPY PACKAGE
• Introduction to Numpy Package
• Array as Data Structure
• Core Numpy functions
• Matrix Operations, Broadcasting in Arrays
MODULE 3: PYTHON PANDAS PACKAGE
• Introduction to Pandas package
• Series in Pandas
• Data Frame in Pandas
• File Reading in Pandas
• Data munging with Pandas
MODULE 4: VISUALIZATION WITH PYTHON - Matplotlib
• Visualization Packages (Matplotlib)
• Components Of A Plot, Sub-Plots
• Basic Plots: Line, Bar, Pie, Scatter
MODULE 5: PYTHON VISUALIZATION PACKAGE - SEABORN
• Seaborn: Basic Plot
• Advanced Python Data Visualizations
MODULE 6: ML ALGO: LINEAR REGRESSSION
• Introduction to Linear Regression
• How it works: Regression and Best Fit Line
• Modeling and Evaluation in Python
MODULE 7: ML ALGO: LOGISTIC REGRESSION
• Introduction to Logistic Regression
• How it works: Classification & Sigmoid Curve
• Modeling and Evaluation in Python
MODULE 8: ML ALGO: K MEANS CLUSTERING
• Understanding Clustering (Unsupervised)
• K Means Algorithm
• How it works : K Means theory
• Modeling in Python
MODULE 9: ML ALGO: KNN
• Introduction to KNN
• How It Works: Nearest Neighbor Concept
• Modeling and Evaluation in Python
MODULE 1: FEATURE ENGINEERING
• Introduction to Feature Engineering
• Feature Engineering Techniques: Encoding, Scaling, Data Transformation
• Handling Missing values, handling outliers
• Creation of Pipeline
• Use case for feature engineering
MODULE 2: ML ALGO: SUPPORT VECTOR MACHINE (SVM)
• Introduction to SVM
• How It Works: SVM Concept, Kernel Trick
• Modeling and Evaluation of SVM in Python
MODULE 3: PRINCIPAL COMPONENT ANALYSIS (PCA)
• Building Blocks Of PCA
• How it works: Finding Principal Components
• Modeling PCA in Python
MODULE 4: ML ALGO: DECISION TREE
• Introduction to Decision Tree & Random Forest
• How it works
• Modeling and Evaluation in Python
MODULE 5: ENSEMBLE TECHNIQUES - BAGGING
• Introduction to Ensemble technique
• Bagging and How it works
• Modeling and Evaluation in Python
MODULE 6: ML ALGO: NAÏVE BAYES
• Introduction to Naive Bayes
• How it works: Bayes' Theorem
• Naive Bayes For Text Classification
• Modeling and Evaluation in Python
MODULE 7: GRADIENT BOOSTING, XGBOOST
• Introduction to Boosting and XGBoost
• How it works?
• Modeling and Evaluation of in Python
MODULE 1: TIME SERIES FORECASTING - ARIMA
• What is Time Series?
• Trend, Seasonality, cyclical and random
• Stationarity of Time Series
• Autoregressive Model (AR)
• Moving Average Model (MA)
• ARIMA Model
• Autocorrelation and AIC
• Time Series Analysis in Python
MODULE 2: SENTIMENT ANALYSIS
• Introduction to Sentiment Analysis
• NLTK Package
• Case study: Sentiment Analysis on Movie Reviews
MODULE 3: REGULAR EXPRESSIONS WITH PYTHON
• Regex Introduction
• Regex codes
• Text extraction with Python Regex
MODULE 4: ML MODEL DEPLOYMENT WITH FLASK
• Introduction to Flask
• URL and App routing
• Flask application – ML Model deployment
MODULE 5: ADVANCED DATA ANALYSIS WITH MS EXCEL
• MS Excel core Functions
• Advanced Functions (VLOOKUP, INDIRECT..)
• Linear Regression with EXCEL
• Data Table
• Goal Seek Analysis
• Pivot Table
• Solving Data Equation with EXCEL
MODULE 6: AWS CLOUD FOR DATA SCIENCE
• Introduction of cloud
• Difference between GCC, Azure, AWS
• AWS Service ( EC2 instance)
MODULE 7: AZURE FOR DATA SCIENCE
• Introduction to AZURE ML studio
• Data Pipeline
• ML modeling with Azure
MODULE 8: INTRODUCTION TO DEEP LEARNING
• Introduction to Artificial Neural Network, Architecture
• Artificial Neural Network in Python
• Introduction to Convolutional Neural Network, Architecture
• Convolutional Neural Network in Python
MODULE 1: DATABASE INTRODUCTION
• DATABASE Overview
• Key concepts of database management
• Relational Database Management System
• CRUD operations
MODULE 2: SQL BASICS
• Introduction to Databases
• Introduction to SQL
• SQL Commands
• MY SQL workbench installation
MODULE 3: DATA TYPES AND CONSTRAINTS
• Numeric, Character, date time data type
• Primary key, Foreign key, Not null
• Unique, Check, default, Auto increment
MODULE 4: DATABASES AND TABLES (MySQL)
• Create database
• Delete database
• Show and use databases
• Create table, Rename table
• Delete table, Delete table records
• Create new table from existing data types
• Insert into, Update records
• Alter table
MODULE 5: SQL JOINS
• Inner Join, Outer Join
• Left Join, Right Join
• Self Join, Cross join
• Windows function: Over, Partition, Rank
MODULE 6: SQL COMMANDS AND CLAUSES
• Select, Select distinct
• Aliases, Where clause
• Relational operators, Logical
• Between, Order by, In
• Like, Limit, null/not null, group by
• Having, Sub queries
MODULE 7 : DOCUMENT DB/NO-SQL DB
• Introduction of Document DB
• Document DB vs SQL DB
• Popular Document DBs
• MongoDB basics
• Data format and Key methods
MODULE 1: GIT INTRODUCTION
• Purpose of Version Control
• Popular Version control tools
• Git Distribution Version Control
• Terminologies
• Git Workflow
• Git Architecture
MODULE 2: GIT REPOSITORY and GitHub
• Git Repo Introduction
• Create New Repo with Init command
• Git Essentials: Copy & User Setup
• Mastering Git and GitHub
MODULE 3: COMMITS, PULL, FETCH AND PUSH
• Code Commits
• Pull, Fetch and Conflicts resolution
• Pushing to Remote Repo
MODULE 4: TAGGING, BRANCHING AND MERGING
• Organize code with branches
• Checkout branch
• Merge branches
• Editing Commits
• Commit command Amend flag
• Git reset and revert
MODULE 5: GIT WITH GITHUB AND BITBUCKET
• Creating GitHub Account
• Local and Remote Repo
• Collaborating with other developers
MODULE 1: BIG DATA INTRODUCTION
• Big Data Overview
• Five Vs of Big Data
• What is Big Data and Hadoop
• Introduction to Hadoop
• Components of Hadoop Ecosystem
• Big Data Analytics Introduction
MODULE 2 : HDFS AND MAP REDUCE
• HDFS – Big Data Storage
• Distributed Processing with Map Reduce
• Mapping and reducing stages concepts
• Key Terms: Output Format, Partitioners,
• Combiners, Shuffle, and Sort
MODULE 3: PYSPARK FOUNDATION
• PySpark Introduction
• Spark Configuration
• Resilient distributed datasets (RDD)
• Working with RDDs in PySpark
• Aggregating Data with Pair RDDs
MODULE 4: SPARK SQL and HADOOP HIVE
• Introducing Spark SQL
• Spark SQL vs Hadoop Hive
MODULE 1: TABLEAU FUNDAMENTALS
• Introduction to Business Intelligence & Introduction to Tableau
• Interface Tour, Data visualization: Pie chart, Column chart, Bar chart.
• Bar chart, Tree Map, Line Chart
• Area chart, Combination Charts, Map
• Dashboards creation, Quick Filters
• Create Table Calculations
• Create Calculated Fields
• Create Custom Hierarchies
MODULE 2: POWER-BI BASICS
• Power BI Introduction
• Basics Visualizations
• Dashboard Creation
• Basic Data Cleaning
• Basic DAX FUNCTION
MODULE 3 : DATA TRANSFORMATION TECHNIQUES
• Exploring Query Editor
• Data Cleansing and Manipulation:
• Creating Our Initial Project File
• Connecting to Our Data Source
• Editing Rows
• Changing Data Types
• Replacing Values
MODULE 4: CONNECTING TO VARIOUS DATA SOURCES
• Connecting to a CSV File
• Connecting to a Webpage
• Extracting Characters
• Splitting and Merging Columns
• Creating Conditional Columns
• Creating Columns from Examples
• Create Data Model










AI is the future, and DataMites helped me step into it! The online Data Science course was easy to follow, and the tutors explained everything clearly. Even after completing my course, the team supported me with placements and I successfully cracked a job! Grateful to DataMites for shaping my career.
I joined DataMites to learn Data Science and gained strong skills in ML, DL, and Statistics. Through my internship at Rubixe AI Solutions, I worked on real-world projects, which helped me land job interviews and an offer. The trainers were very supportive and explained every concept clearly. Thanks to DataMites, my data science journey was smooth and successful.
My mentor, a DataMites alumnus, suggested I join the Data Science course, and it was one of my best decisions! The offline classes were interactive and full of guidance, and I got the chance to intern at Rubixe AI Solutions. The placement team was very supportive and helped me perfect my resume. Truly thankful to DataMites for this amazing learning journey.
I joined DataMites after completing my engineering in Computer Science and became a Certified Data Scientist. With their support, I completed an internship at Rubix AI Solutions and now work as an AI intern at Inventor Hub. DataMites made learning statistics and data science easy with clear guidance and great materials. I’m truly thankful for their support.
I joined DataMites for the Certified Data Scientist online course, and it was a great experience! The real-time projects helped me apply my learning practically, and the placement support added real value to my career restart after 8 years. DataMites is the perfect platform to learn, grow, and begin your data science journey.
I joined DataMites for the Data Science course and learned Python, SQL, Machine Learning, and Deep Learning through hands-on projects. The trainers are excellent at explaining concepts clearly. The placement team is very supportive and provides great opportunities thanks to DataMites for helping me start my data science journey.
I joined DataMites after my B.Tech when I developed an interest in Data Science and Machine Learning. The training was well-structured, and I even got an internship opportunity that helped me gain real experience. The placement team was super supportive and guided me through every step. Thanks to DataMites, I’m now placed at Horizon Broadband Pvt. Ltd.
I joined DataMites after completing my BCA, and it was the best decision for my data science career! I learned Python, SQL, Machine Learning, Deep Learning, and NLP, and worked on several capstone and client projects that gave me real-world experience. The trainers and team were always friendly and supportive, patiently clearing all my doubts. Thanks to DataMites, I’m confident and job-ready in data science
I started my data science journey with DataMites, and it’s been an amazing experience! The Certified Data Scientist Program helped me learn everything from scratch through hands-on projects and an internship. The placement team was incredibly supportive, always ready to clarify my doubts. Thanks to their guidance, I successfully got placed. Highly recommend DataMites to anyone starting their data science career
Enrolling at DataMites was one of the best decisions I made for my career. Coming from a freelance writing background with no prior technical experience, I was initially unsure about stepping into the field of data analytics. But DataMites made the transition smooth and achievable. I’d highly recommend them to anyone looking for a guided, industry-ready data analytics course. A true DataMites success story!
Data science is an interdisciplinary field that combines scientific methods, processes, algorithms, and systems to extract knowledge and insights from structured and unstructured data.
Learning data science is important because it enables individuals to extract valuable insights from data, make data-driven decisions, solve complex problems, and drive innovation in various industries.
Key skills needed to become a data scientist include proficiency in programming languages like Python or R, statistical analysis, machine learning, data visualization, problem-solving, and domain knowledge.
One can effectively acquire data science knowledge through a combination of formal education, online courses, self-study, hands-on projects, participating in data science competitions, and continuous learning from available resources and communities.
Common challenges faced by data scientists include dealing with large and messy data, data privacy and security concerns, selecting appropriate algorithms and models, interpreting and communicating results effectively, and staying updated with the rapidly evolving field.B
The cost of a data science course in Gwalior can vary depending on the institution and program, but it generally ranges from INR 40,000 to INR 50,000.
The requirements for enrolling in a data science course typically include a bachelor's degree in a related field (such as computer science or statistics), programming skills, mathematical aptitude, and sometimes specific prerequisites or entrance exams set by the institution.
The field of data science offers promising career prospects, with opportunities in industries such as healthcare, finance, e-commerce, technology, and more. Data scientists can work as data analysts, data engineers, machine learning engineers, AI researchers, and consultants, among other roles.
Obtaining a certification in data science is important as it demonstrates proficiency and credibility in the field, enhances job prospects, validates skills and knowledge, and provides a competitive edge in a rapidly growing job market.
Yes, there is a high demand for data science courses due to the increasing need for skilled professionals who can handle and analyze large volumes of data, derive insights, and drive data-based decision-making in organizations.
Data science offers good career security as the demand for skilled data scientists continues to grow, and data-driven decision-making becomes essential across industries. However, staying updated with emerging technologies and continuous learning is crucial for long-term career growth.
The level of difficulty in studying data science can vary depending on an individual's background and prior experience. It requires a solid understanding of mathematics, statistics, programming, and concepts related to data analysis and machine learning, which may require dedicated effort and practice.
Python alone can suffice for data science as it is a widely used programming language in the field, offering extensive libraries and frameworks for data manipulation, analysis, machine learning, and visualization.
SQL knowledge is beneficial for data scientists as it enables efficient data extraction, transformation, and querying from relational databases, which are commonly used in many organizations. It complements the overall data science skill set.
A strong statistical background is crucial in data science as it forms the foundation for understanding and applying various data analysis techniques, hypothesis testing, experimental design, and interpreting results accurately. Statistical knowledge helps in making meaningful inferences from data.
DataMites in Gwalior is an exceptional option for individuals seeking a Data Science course. It distinguishes itself through its proficient faculty, a comprehensive curriculum covering a wide range of data science topics, a strong focus on practical learning through hands-on experiences, industry-aligned projects, and unwavering assistance in securing placement opportunities.
The DataMites Certified Data Scientist Course in Gwalior warmly welcomes individuals possessing a solid background in mathematics and programming, as well as those with prior exposure to statistics, engineering, or similar fields. By adopting this inclusive approach, the course accommodates a diverse group of participants who harbour aspirations of building successful careers in the ever-evolving realm of Data Science.
Considering the meticulously crafted curriculum, experienced faculty, interactive hands-on learning experiences, practical project assignments, and industry-centric training, choosing the DataMites data science course in Gwalior is a prudent decision. This comprehensive program effectively enhances your understanding and proficiency in the field of data science, subsequently amplifying your employment prospects.
The course duration spans over 8 months with 700 learning hours, which includes 120 hours of live online training.
Upon successfully finishing the data science course in Gwalior, students are awarded the highly regarded IABAC certification, which carries significant global recognition. This esteemed certification serves as a valuable credential, bolstering job prospects and facilitating participation in internship programs, thereby opening up abundant opportunities in the field of data science.
Upon the successful completion of the course, DataMites offers robust support and guidance for placements through their dedicated Placement Assistance Team (PAT). The PAT provides personalized assistance, ensuring individuals receive comprehensive support in securing well-suited job placements. This tailored support significantly enhances employment prospects, unlocking a plethora of opportunities in the field of data science.
DataMites offers an extensive range of data science courses in Gwalior that cover a diverse array of topics. These courses include Data Science Foundation, Data Science for Managers, Data Science Associate, Diploma in Data Science, Python for Data Science, Statistics for Data Science, Data Science Marketing, Data Science Operations, Data Science Retail, Data Science for HR, Data Science with Finance, and Data Science.
DataMites is renowned for its exceptional team of industry-expert educators who possess extensive experience and profound knowledge in the field of data science. These instructors are highly qualified, hold prestigious certifications, and bring their extensive expertise to the classroom, delivering outstanding instruction. Their guidance empowers students to cultivate a comprehensive understanding of the subject matter.
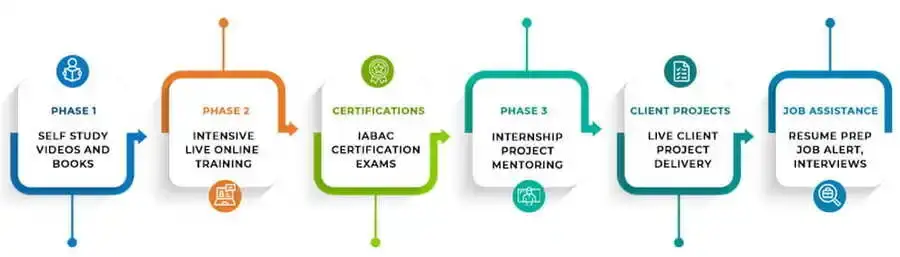
DataMites understands the diverse preferences of students and offers flexible learning options to cater to their needs. They provide a variety of choices, including live online sessions, self-paced learning, and on-demand classroom training. This flexibility enables individuals to select the learning approach that aligns best with their requirements, making it convenient for them to pursue their data science education.
DataMites offers a thorough explanation of its training approach, ensuring students have a clear understanding of the training process and its components. Moreover, they provide a complimentary demo class, giving individuals an opportunity to fully comprehend the training methodology. This enables prospective students to assess the quality and suitability of the training before making a commitment, ensuring a well-informed decision.
Learning Through Case Study Approach
Theory → Hands-on → Case Study → Project → Model Deployment
The payment mode available for the data science course in Gwalior through:
DataMites presents its Data Science Course in Gwalior at different price points, offering a range of options to cater to diverse preferences. These include INR 35,000 for live online training, INR 21,000 for blended learning, and INR 44,000 for on-demand classroom training. This flexible pricing structure empowers individuals to select the plan that aligns with their budget and preferred mode of learning.
In order to obtain the participation certificate and book the certification exam, it is necessary to provide valid photo identification proofs such as a National ID card or a Driving license. These identification proofs play a vital role in verifying the authenticity and accuracy of the certification process.
According to a PayScale report, the salary of a data scientist in India ranges from INR 9,10,238 per year.
Data science learners across Gwalior have easy access to DataMites training at the center located at Coworking, Sorted Square, Panchwati Vastra Nagar, Roshni Ghar Mohalla, Lashkar, Gwalior, Madhya Pradesh 474009. The center is well connected to several nearby residential localities including Lashkar (474001), Morar (474006), Thatipur (474011), Bahodapur (474012), Kampoo (474002), Hazira (474003), Vinay Nagar (474008), City Centre (474011), Gole Ka Mandir (474005), and Shinde Ki Chhawani (474001), enabling students from different parts of Gwalior to easily join offline Data Science training programs with practical, industry-focused learning.
DataMites Gwalior offline training center is located at Coworking, Sorted Square, Panchwati Vastra Nagar, Roshni Ghar Mohalla, Lashkar, Gwalior, Madhya Pradesh 474009.
The DataMites Placement Assistance Team(PAT) facilitates the aspirants in taking all the necessary steps in starting their career in Data Science. Some of the services provided by PAT are: -
The DataMites Placement Assistance Team(PAT) conducts sessions on career mentoring for the aspirants with a view of helping them realize the purpose they have to serve when they step into the corporate world. The students are guided by industry experts about the various possibilities in the Data Science career, this will help the aspirants to draw a clear picture of the career options available. Also, they will be made knowledgeable about the various obstacles they are likely to face as a fresher in the field, and how they can tackle.
No, PAT does not promise a job, but it helps the aspirants to build the required potential needed in landing a career. The aspirants can capitalize on the acquired skills, in the long run, to a successful career in Data Science.